Supercharged Laravel: Action Processors, Data Caching, and Model Composites


Laravel has a lot of detractors, but there are two things of which any developer can be certain: a) whether you like it or not, PHP is undoubtedly the most widely deployed language of the web (read: employability), and b) it's unbeatable for rapid prototyping of ideas. What started as a HTML templating system has bloated into a replication of Java, featuring some of the most popular frameworks in use today.
A good engineer is never snobby when it comes to picking the right tool for the job. When you have time and need performance, it's C++, Java, or Go. When you have speed and don't need performance yet, you're looking at Python or PHP. If you're a latte-drinking artisan wearing a beanie, you're only ever going to whine on about Node, Scala, or the latest fashionable paradigm.
Misunderstanding Model, View, Controller
What's also unimpeachable about most modern frameworks is they are a variant of the MVC pattern from 1979 developed by Trygve Reenskaug. The idea of MVC is an application is split into three distinct parts, based on the roles they perform and "layers" they inhabit.
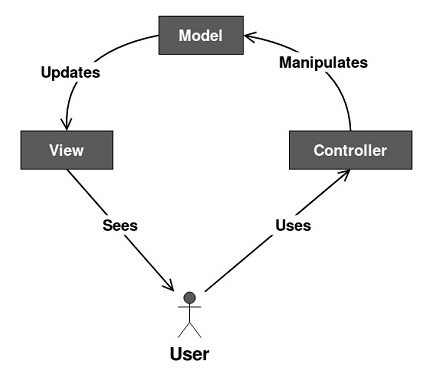
A model almost always translates to the underlying data of an application. And by that, we typically mean the database and its content.
A view is what a user sees. It could be an HTML page, a screen in a desktop application, a storyboard in a mobile app, or any other visual element displayed to person using the software.
A controller is the middle piece of the sandwich which handles communication between the model and the view. Typically it's the "brain" or the decision-making apparatus. It handles something the user asks to do.
The Evolution of the MVC Maze
By 1987, Joëlle Coutaz had developed Presentation Abstract Control (PAC), which was then rebooted in 2000 via Javaworld magazine as Hierarchical Model View Controller (HMVC) to support widgetization of visual content.
In 1996, IBM subsidiary Taligent published their idea for the Model View Presenter (MVP) pattern, where all the clever processing was pushed towards the UI.
Around 10 years later, Microsoft engineer John Gossman came up with Model View ViewModel (MVVM) which attached models directly to the view, and Martin Fowler suggested Model View Presenter ViewModel (MVPVM).
ORMs: fuzzy logic abstraction for RDBMS
Additionally coupled into most frameworks are database management packages, known colloquially as Object-Relational Mapping (ORM), which gained popularity through Ruby On Rails.
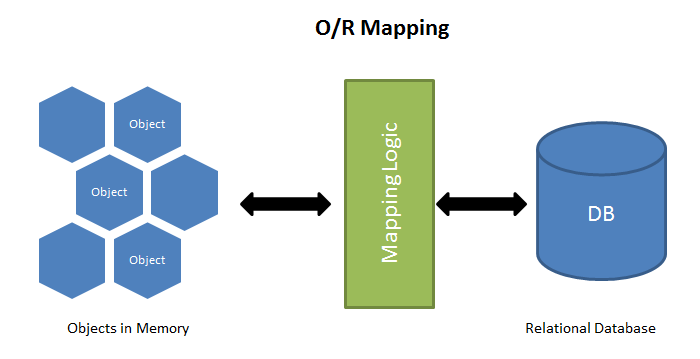
"An object-relational mapper (ORM) is a code library that automates the transfer of data stored in relational databases tables into objects that are more commonly used in application code."
The undoubted Daddy - in terms of usage, is ActiveRecord (again by Martin Fowler), where a single row from a database table is "mapped" or "represented" as an object. No more raw SQL as strings, just a simple save().
The Ongoing Nightmare of Spaghetti Code
PHP has an unfortunate legacy of being a scrappy interpreted scripting language like Perl, used extensively on the command line as procedural code. While in itself it may have advantages generically, procedural detritus in PHP is almost always line-by-line spaghetti which is abstraction-less, as well as the ugliest kind of garbage you can ever deal with. Examples abound:
<?php
$payload = '{ "products": [';
foreach ($products as $product) {
$payload .= $product->toJson() . ',';
}
$payload = substr($payload, 0, \strlen($payload) - 1);
$payload .= ']}';From: https://shitcode.net/worst/language/php
What's unfortunately happened is this garbage has ended up in controllers; using them like an envelope for migrated logic. There's such chaos as to whether to put functions in models, or SQL in views, it's the only supposedly logical place to stuff the horror you've had to write into.
Not only has it ended up there inappropriately, it's often 1000+ lines of this kind of unmaintainable evil. It's the Fat Controller.
<?php
class SomethingController {
function index ()
{
// validate
// if validaton fails return errors
// if validation pass do the following
$booking = getDetailsFromRepository($id)
// check if client is paying with credits
// process booking with credits
// update client credids
// check if any errors with stripe and return readable message to user
// else process booking with credit card
// set all date for Stripe::charge
// capture charge
// check if any errors with stripe and return readable message to user
// if everything went well
// save payment in db
// save booking
// return success message to user
}
}The problem is it's not the controller's job. All the controller is meant to do is receive a user request, send it to the model, and feed the result back to the view. It's a mediator. The clever stuff is black-boxed into reusable modules, services, and/or other types of functional units which are decoupled and independent from other parts of the application.
1. Introducing Action Processors
When you're working with databases, you have 4 distinct operations:
- CREATE (insert a row)
- READ (browse, retrieve or read one or more rows)
- UPDATE (obvious)
- DELETE (soft: mark a row with a deletion date; hard: remove entirely)
Sites like Wikipedia quickly realised 95% of all operations are READ-related, and can be cached with software like Varnish rather than be repetitively and inefficiently retrieved on-the-fly. Inserts, updates, and deletes are the only ones done "live", and subsequently requiring a refresh of the data.
Enter Action Processors to end the mess and get the logic out of controllers.
An Action Processor provides browsing of records, updating one or more records, and its relations, or the creating of records. They are browsers, creators, updaters, or deleters. We could make them literally anything else we want, but in this example, we're looking at database operations - which form the majority of logic in web applications.
Setting Up The Basic Pattern
Ideally, we want to self-enclose all our functionality (modules, services etc), but for simplicity, here's the clearest explanation. First, we set up a base class we can extend for each type. We don't have to, we maybe even shouldn't, but there's no harm in it.
Note: this isn't the definitive and authoritative best-practice way to do things. It's used for explaining the idea only.
In app/Processors, we place BaseProcessor.php as our handy God-class which can share universal functionality across all its children:
<?php
namespace App\Processors;
abstract class BaseProcessor {
}
Then, we add Browser.php, Creator.php, Updater.php, and Deleter.php:
<?php
namespace App\Processors;
abstract class Browser extends BaseProcessor {
}Of course, we are free to enforce contracts for each via interfaces if we so desire.
Rolling out Individual Processors
Next, we want to encapsulate individual "actions" into classes we can inject in the controller whenever and wherever we like.
A browser has two jobs: a) preparing a set of records, or b) setting up the required data for viewing an individual item.
<?php
namespace App\Processors\Browsers\User;
use App\Models\User;
use App\Processors\Browser;
use Illuminate\Http\Request;
class UserBrowser extends Browser {
public function __construct () {
parent::__construct ();
}
public function setup ( Request $request, User $user )
{
// get the user record
return [
'user' => $user,
];
}
public function prepare ( Request $request )
{
// get the recordset
return $users;
}
public function view_vars ( Request $request )
{
return [
'q' => $request->input ('q'),
'orderby' => $request->input ('orderby', 'first_name'),
'order' => $request->input ('order', 'ASC'),
]);
}
}
A creator also has two jobs: a) setting up presets used in a form, and b) handling a payload.
<?php
namespace App\Processors\Creators\User;
use App\Processors\Creator;
use App\Http\Requests\StoreUserRequest;
use App\Models\User;
class UserCreator extends Creator {
public function __construct ()
{
parent::__construct ();
}
public function setup () : array
{
return [
// anything you need for the form
];
}
public function handle ( StoreUserRequest $request )
{
$this->created = $this->manager->create ($request->all());
return $this->created;
}
}An updater is almost identical in its role: a) setting up the edit form, and b) handling the subsequent payload. For consistency, we could package the setup with the creator's sibling method.
<?php
namespace App\Processors\Updaters\User;
use App\Http\Requests\UpdateUserRequest;
use App\Models\User;
use App\Processors\Updater;
use Illuminate\Http\Request;
class UserUpdater extends Updater {
public function __construct ()
{
parent::__construct ();
}
public function setup ( Request $request, User $user ) : array
{
return [
'user' => $user,
]
}
public function handle ( UpdateUserRequest $request, User $user )
{
$this->updated = $this->manager->update ($params, $user->user_id);
return $this->updated;
}
}A deleter only has one job: handle a payload.
<?php
namespace App\Processors\Deleters\User;
use App\Processors\Deleter;
use Illuminate\Http\Request;
use App\Models\User;
class UserDeleter extends Deleter {
public function __construct ()
{
parent::__construct ();
}
public function handle ( Request $request, User $user )
{
}
}
Injecting Processors Into Controller Methods
Now we have all our logic packaged up, we can inject each processor individually wherever we like, as many times as we like. For example, if we were updating a user record in the UI as well as the API, we have no need to write the same code twice.
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Models\User;
use App\Http\Requests\StoreUserRequest;
use App\Http\Requests\UpdateUserRequest;
use App\Processors\Browsers\User\UserBrowser;
use App\Processors\Creators\User\UserCreator;
use App\Processors\Updaters\User\UserUpdater;
use App\Processors\Updaters\User\UserDeleter;
class UserController extends Controller
{
public function index ( Request $req, UserBrowser $browser )
{
return view ( 'users.index',
array_merge ( $browser->prepare ($req), $browser->view_vars ($req))
);
}
public function create ( Request $req, UserCreator $processor )
{
return view ( 'users.create', $processor->handle ($req) );
}
public function show ( Request $req, UserBrowser $browser, User $user )
{
return view ( 'users.create', $browser->setup ($req, $user) );
}
public function edit ( Request $req, UserUpdater $processor, User $user )
{
return view ( 'users.edit', $browser->setup ($req, $user) );
}
public function store ( StoreUserRequest $req, UserCreator $processor )
{
$created = $processor->handle ($req);
return redirect ()->route ('users.show', $created->id)
->with ('success', 'Created user successfully');
}
public function update ( $req, UserUpdater $processor, User $user )
{
$updated = $processor->handle ($req);
return redirect ()->route ('users.show', $updated->id)
->with ('success', 'Updated user successfully');
}
public function delete ( Request $req, UserDeleter $processor, User $user )
{
$processor->handle ($req);
return redirect ()->route ('users.index')
->with ('success', 'Deleted user successfully');
}
}
Each of the processors are type-hinted - as the models are in their binding to the route - so they are decoupled from the actual MVC structure and can vary independently if needed. If we need two different versions, we can simply change them up at will. If we need to change something in the way the API handles a record update, we don't have to get frustrated with sync'ing it with the UI or errors resulting from inconsistencies.
Of course, you can go even further by pre-binding the action to the controller method via injection, as the model is bound to it. All we are trying to achieve at this point is to take the logic out of the controller itself and allow it to do its single job: dealing with the request, sending it to a logic end-point, and feeding it back to the view.
2. Introducing Data Cachers
A database can only handle a certain number of simultaneous pooled connections and easily times out with a hug of death when heavily publicised. At that point, it's time to get into the fight of how to handle session persistence behind load balancers with multiple persistence databases.
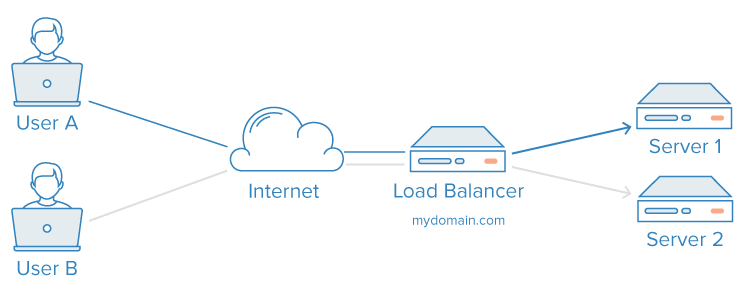
It becomes apparent that continuously browsing and retrieving the same paginated recordsets, or even the same individual record views, is highly inefficient. You only need to retrieve the same unchanged record once.
Now you're off to the races: it's time to use multiple application servers behind a load balancer, and use RAM-based cache/queue servers like memcached or redis. You've got a brand new elastically-scalable cluster of 100 redis docker instances, sat on top of a cluster of 5 database instances set up to master/slave replication. Maybe you even have elasticsearch, beanstalkd or Hadoop in there too.
You need a method of storing your paginated recordset in your RAM cache, and flushing it when it's updated.
Approach A: The Repository Pattern
If you're on a simplistic setup, the first way to deal with the caching problem is to use a package which can abstract your data model into a repository pattern which has built-in caching functionality.
Example: https://github.com/andersao/l5-repository
"A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction. Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes."
(https://martinfowler.com/eaaCatalog/repository.html)
In the Github package above, a repository is simply 2 files:
The repository class, which can auto-load Criteria classes for filtering requests:
<?php
namespace App\Repositories;
use Prettus\Repository\Eloquent\BaseRepository;
use Prettus\Repository\Criteria\RequestCriteria;
use App\Helpers\Contracts\Repositories\UserRepositoryContract;
use Prettus\Repository\Contracts\CacheableInterface;
use Prettus\Repository\Traits\CacheableRepository;
use App\Models\User;
use App\Validators\UserRepositoryValidator;
class UserRepository extends BaseRepository
implements UserRepositoryContract, CacheableInterface
{
use CacheableRepository;
protected $cacheMinutes = 3600;
//protected $cacheOnly = ['all', ...];
//or
//protected $cacheExcept = ['find', ...];
public function model()
{
return User::class;
}
public function boot()
{
$this->pushCriteria(app(RequestCriteria::class));
}
}
Then its interface (or contract):
<?php
namespace App\Helpers\Contracts\Repositories;
use Prettus\Repository\Contracts\RepositoryInterface;
interface UserRepositoryContract extends RepositoryInterface
{
//
}
And optionally, individual Criteria abstracted into re-usable logic:
<?php
namespace App\Criteria;
use Prettus\Repository\Contracts\CriteriaInterface;
use Prettus\Repository\Contracts\RepositoryInterface;
class OrderByCriteria implements CriteriaInterface
{
public $order_field;
public $order_dir;
public function __construct ( $order_field, $order_dir )
{
$this->order_field = $order_field;
$this->order_dir = $order_dir;
}
public function apply ( $model, RepositoryInterface $repository )
{
return $model->orderBy ( $this->order_field, $this->order_dir );
}
}Repository packages are simple, reusable, and in most cases, can entirely handle the communication between the cache cluster in a transparent and simplistic way without invoking additional logic in the application itself.
Approach B: Per-Request Data Caching
If you prefer a more granular approach, it's of course entirely possible to slice cached data into smaller units which can spread across the cluster as required. The objective of the cache is to lift the load from the database so you can use less server resources and have a smaller group to maintain. A cache can elastically store keys which have already been pre-processed for use in the view.
With a small modification to our browser processor class, we can instruct it to conditionally access the data we need:
a) If the data is present in the cache (HIT), load it from there;
b) If the data is not present in the cache (MISS):
i) retrieve it from the database and,
ii) store it in the cache for the next request.
And of course, if the data is updated, flush it from the cache and re-store it.
A simplistic version of our parent Browser class (where we use the URL as the key, as an unwise strategy) might look like so:
<?php
namespace App\Processors;
use Illuminate\Http\Request;
use App\Exceptions\NoCachedDataException;
abstract class Browser {
public function data_cache ( Request $request )
{
if ( cache ()->has (md5 ($request->fullUrl()) ) ) {
view ()->share ('DATA_CACHE', md5 ($request->fullUrl()));
return cache ()->get (md5 ($request->fullUrl()) );
}
throw new NoCachedDataException;
}
public function store_cached_data ( Request $request, $data )
{
cache ()->put (md5 ($request->fullUrl()), $data, 10);
}
}We can then programmatically tell our individual processor to load data on a conditional basis by specifying an interface:
<?php
namespace App\Processors\Browsers\User;
use Illuminate\Http\Request;
use App\Processors\Browser;
use App\Contracts\ShouldTryCache;
use App\Exceptions\NoCachedDataException;
class UserBrowser extends Browser implements ShouldTryCache {
public function prepare ( Request $request)
{
try {
return $this->data_cache ($request);
} catch ( NoCachedDataException $e ) {
// get the data from the DB and store it to the cache
}
}
}Using this approach, we can manage what data is pushed into, and pulled out, of our chosen cache on a per-record basis. Our cache logic is separate from our retrieval logic, and our content can also be separated conditionally from that, in turn. We can apply it to everything (globally) if necessary.
If we have specific stress on particular parts of the application, we can apply a layer of logic to relieve it without necessarily affecting all of our data retrieval processes.
If the data required by the view requires CPU time (transformation, re-formatting etc), it can be dumped into the cache without repeating the same server-punishing crunch on each request.
Our goal remains the same: minimise repetitive trips to the database to retrieve the same data, which should be in a different, faster part of the network.
Once the processed data is out of the back-end in the format which is required and stored closer to the view, we can combine it with:
a) Page caching of the entire HTML output, and:
b) Read-caching of that output with Varnish.
3. Introducing Model Composites
An ActiveRecord "table" being mapped into an object doesn't have to correspond to a single table at all. One of the most powerful features of all relational databases is the concept of a view into the data.
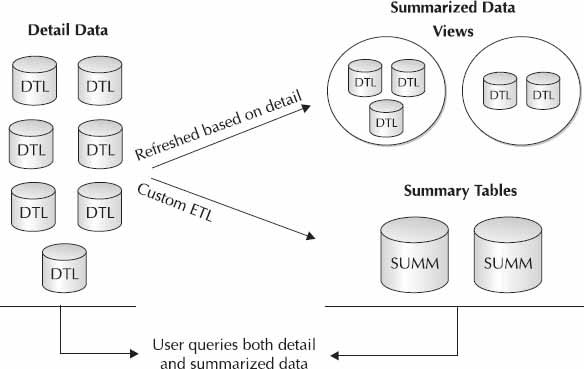
"A database view is a searchable object in a database that is defined by a query. Though a view doesn’t store data, some refer to a views as “virtual tables,” you can query a view like you can a table. A view can combine data from two or more table, using joins, and also just contain a subset of information. This makes them convenient to abstract, or hide, complicated queries."
Relational Data Integrity Creates Logical Fragmentation
The way we need to store the data in the RDBMS may be utterly useless in an app where we need to access it in one complete record. We can attempt to deal with that with lazy/eager loading or using multiple JOIN statements, but the former adds load to our database queries, and the latter gets messy quickly.
Let's take the example of a customer record. We might split the data into a few different tables with foreign keys:
- Master customer records;
- Mailing addresses;
- Postal/Zip code records;
- Phone numbers (inc. extensions etc);
- Purchases;
In a typical ActiveRecord ORM, each table corresponds to one table. We have models for customer records, addresses, postal lookups, phone numbers, and purchases. This isn't ideal; it works for the database integrity, but it sucks when loading the data into an application UI which then needs to link it together programmatically with CPU time.
Assembling Database Views Into Models
A view allows us to make a composite of these tables into a "virtual table" which is more efficient, and allows us to maintain relational integrity of the underlying data. Instead of doing multiple lookups and linking the records programmatically, we can ask the database to do the hard work for us.
In Postgres, we could could create a schema called composites and specify ugly SQL such as:
CREATE OR REPLACE VIEW composites.customer_record_full AS
SELECT
customers.*,
addresses.line1,
addresses.city,
addresses.locality,
zipcodes.zip,
telephones.primary,
telephones.cell,
(SELECT COUNT(*) FROM purchases WHERE purchases.customer_id = customers.customer_id) AS num_purchases,
(SELECT MAX (purchase_date) FROM purchases WHERE purchases.customer_id = customers.customer_id) AS last_purchase
FROM customers
LEFT JOIN addresses ON customers.address_id = addresses.address_id
LEFT JOIN zipcodes ON addresses.zipcode_id = zipcodes.zipcode_id
LEFT JOIN telephones ON telephones.customer_id = customers.customer_idObviously this isn't the best way to retrieve aggregate data, but it illustrates the need for lateral data which could be included in a single "virtual" table.
Within Laravel, we'd keep track of the database view files using migrations, as per usual: individual .sql files are stored in the database/ folder.
<?php
use Illuminate\Support\Facades\Schema;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Database\Migrations\Migration;
class AddCustomerViews extends Migration
{
public function up()
{
\DB::statement (
file_get_contents (
database_path ('composites/customer/full_record.sql')
)
);
}
public function down()
{
\DB::statement ('DROP VIEW IF EXISTS composites.customer_record_full');
}
}Then, within our app/Models/ folder, we can still use ActiveRecord model classes as normal, but we also introduce a new composites/ directory for models which access the database view composites as their "table". Naturally, we can map these into a repository, or cache items as before.
<?php
namespace App\Models\Composites\Customer;
use App\Models\Composites\BaseComposite;
use App\Helpers\Contracts\Composites\CompositeContract;
class FullRecord extends BaseComposite implements CompositeContract
{
protected $table = 'composites.customer_record_full';
protected $primaryKey = 'customer_id';
}However, there are important things to note with database views:
a) They typically offer read access only, meaning the underlying models must be operated on separately (e.g. with a stored procedure, or application logic).
b) They often involve dependencies on each other which can be hard to maintain. If one view references another (e.g. to optimize performance), it can get painful.
The Nuclear Option: Materialized Views
There are, on many occasions, despite their usefulness, database views which are so insanely complex and expensive they are slower than CPU time or loading relations within objects. Examples might be aggregating rows into columns (pivot table crosstab queries), queries which require full table scans, and so on.
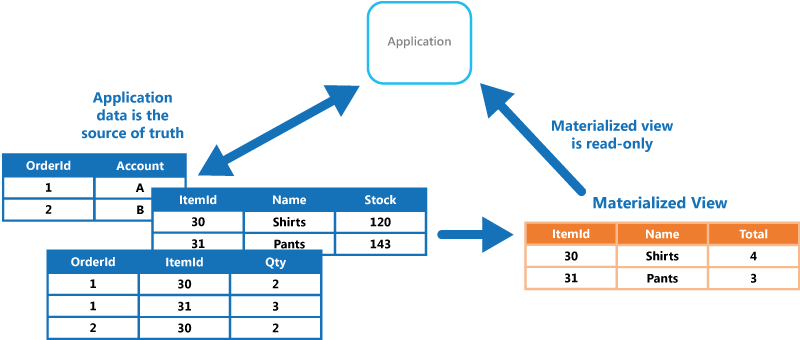
When you're dealing with a query which is too brutal for a "live" view, and is also too expensive to do "live" within code, there's the option to materialize it into static, cached data - like a normal table. Materializing a view is essentially dumping the full output into a semi-permanent virtual table as a one-time operation.
"In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function."
This has the advantage of massively increasing performance, but the downside it needs to be entirely refreshed when things change. Oracle and Postgres are two RDBMS engines which do it natively.
Let's take the ugliest example anyone would dread. Crosstab comes to mind. In this one, we're going to use Postgres' filter function for selective aggregates and produce a monthly report on each customers' total purchase values with month names as columns (yuck). Probably because someone in accounting wanted it horizontal.
CREATE MATERIALIZED VIEW reports.monthly_purchases AS
SELECT
sum(product_price) filter(where month = 1) as jan,
sum(product_price) filter(where month = 2) as feb,
sum(product_price) filter(where month = 3) as mar,
sum(product_price) filter(where month = 4) as apr,
sum(product_price) filter(where month = 5) as may,
sum(product_price) filter(where month = 6) as jun,
# and so on
FROM purchases
GROUP BY customer_id
WITH NO DATA;Crucially, WITH NO DATA allows us to create the structure without running the query, so we can add things like indexes. When we want to populate the view, we initially run:
REFRESH MATERIALIZED VIEW reports.monthly_purchases;Which will lock the data against any queries and fill up the "virtual table" as a cache of the query results. On subsequent refreshes, we can "upsert" data with a slight tweak if we add a UNIQUE index to it first:
REFRESH MATERIALIZED VIEW CONCURRENTLY reports.monthly_purchasesThis statement needs to be triggered in the same way as when a cache is flushed, i.e. when records are altered. We can use Laravel's in-built events, listeners, or observers, if required, which can trigger an asynchronous job.
Often materialized views on slower DB instances can take 5-10mins to re-build if the query is complex. If a queue mechanism is to be used, we also need to take into account the frequency of updates: if a user makes 20 changes in 10 minutes, the view is being heavily over-stressed - so it's more sensible to specify a regular update/refresh (e.g. every 1-10mins, 1hr etc, depending on how long it takes to regenerate).
Something like pg_cron is helpful in that circumstance if you don't want to rely on an external scheduler like cron.
Ideas Without The Means To Test Them Are Useless
Laravel and Ruby On Rails' strength lies in their ability to allow large available pools of developers to quickly create prototypes which can be interrogated for their validity, and changed to better forms. They do lack performance and scalability, for sure; for example, loading the entire framework per request is incredibly punishing, as is not being able to thread or spawn processes. While you might manage 3000 transactions per second in Laravel, you would easily see 16,000 with Go.
Asynchronous event-based frameworks such as Swoole go some way to address this, particularly when Opcache can be used to avoid repetitive trips to the interpreter.
Each tool is different. Each team is different. Each client is different.
In some projects, you might need to work at enormous speed to examine or prove an idea. In others, the database team might want full control of the data layer with stored procedures and custom reports which deny you control over the model.
Code is useless if its entire purpose is producing code; it should be there to enhance productivity and accelerate creativity.