ScreenJSON: Screenplays That Computers Understand


ScreenJSON is a data model and object notation/interchange syntax for screenplays. In essence, it is “screenplays for computers”.
- Word processors help humans to author scripts.
- PDFs help humans to publish and read scripts.
- ScreenJSON helps computer systems understand and analyze scripts.
For the impatient, the documentation is here:
https://screenjson.com
Why the data-driven approach is necessary
In the 1930s, screenplays were written with a typewriter, by qualified insiders who understood the Warner print formatting. In the desktop PC and web age, anyone with a copy of Final Draft Pro can produce a script. The market is flooded, and quality has nose-dived. Everyone is on the lookout for the new best thing out there, but overwhelmed with the material that needs coverage and triage.
As Netflix’s success has shown, in the digital era, film is a data business.
And as Adobe Story’s Pace analysis (https://helpx.adobe.com/story/help/pace-beta.html) has shown, linguistic analysis can be extremely helpful to writers.
Scenario A: Too Many Scripts, Not Enough Time
You are a development executive at a major studio. You receive 200 script submissions a week, in the post, via email, and online (e.g. the Black List). You have 10 readers, each processing 20 scripts a week, or 4 a day, at a cost of $50/script. Each reader can do 1 coverage in the morning, and another in the afternoon. Just keeping them at work costs you $40,000 a month, and you still have 200 reviews on your desk at the end.
Most get a PASS. 15% of them are CONSIDER. But 1-2 get a RECOMMEND. You can't produce them all - you need to prioritize. How can you run all 200 through a mill to get to the RECOMMEND pieces faster?
You’ll always, always need the human element. But before all of that, there are basics.
Scenario B: 20 Departments Doing 20 Different Breakdowns
Not everyone needs to know everything: mainly money guys, producers, the director, and DoP. Actors just need sides for their audition. The armorer just needs to know when guns are featured. The Propmaster and Location Manager need lists. Background actors need the scene they’re in.
So each department goes to work on their own individual breakdown of the script. This is just insanity. It takes days to manually note it all down, and it’s pointless. The Director marks up his shooting script, the DoP marks up his shot list for each scene, and so on.
Scenario C: Not Being Able to See The Forest
A writer can sometimes take 10+ years to produce the first draft, and the script is never finished, even after 400 revisions/versions and twice as many mark-ups. Working on a 120 page document can be draining, and it’s too easy to lose perspective.
Software can help provide a instant “Helicopter View” for editorial and scheduling, on top of providing insight into plotlines, weak spots, and opportunities a human’s conditioned eyes would miss.
Scenario D: Needing To Mark Up Screen & Interactivity Technology
Film is no longer 35mm negative. Digital technology is changing everything every year. Amongst the things we now need to describe are:
- 3D perspective (e.g. background/foreground focus etc)
- 360 VR perspective (e.g. Oculus)
- VFX plates & CGI characters
- Multi-angle video streams (from DVD)
- Sensual perception extension (e.g. Motion seating)
- Video On-Demand “Rabbit Hole” navigation through themes/screen elements
- Dynamic product placement (e.g. purchase item in this scene)
Scenario E: Identifying Trends, Patterns, & Past Success
Computers can process a lot of textual data very quickly: we no longer need a human to spend 2hrs on a script. We can put 500 scripts through the mill, and answer business questions of the past, and estimate future strategy/performance.
- Are we producing too much crap?
- Is the gore level getting worse and desensitizing the audience?
- What are the common elements to the most successful scripts we’ve produced?
- What percentage of characters are stereotypical?
- How often does a character appear across titles, and is the continuity intact?
- What subjects haven’t we covered?
- Which writers produce the strongest audience response?
What can you do with analysis?
Quality Assurance
- Spell checking/scoring
- Grammar checking/scoring
- Plagiarism checking
- Format checking
- Gender balance/bias (Bechdel)
- Poor writing (cliche, alliteration etc)
- Profanity occurrence
- Annotation scoring
Visualization
- Scene cards
- Arc structure (key plot/page markers)
- Relationship graphing
Statistical Analysis (Breakdown) & Named entity recognition (NER)
- Scenes (+ frequency/occurrence)
- Characters (+ frequency/occurrence)
- Locations (+ frequency/occurrence)
- Props (+ frequency/occurrence)
- S/VFX (+ frequency/occurrence)
- Storyboard & asset association
- Author contribution frequency
- Revision comparison (Diff)
Reprocessing
- Import/export across applications
- Dynamic compilation (per user)
- Group/role access management
- Paragraph redaction
- Document/scene encryption
Advanced: Natural Language Processing
- Story/scene pace, energy, & excitement
- Originality
- Dialogue sophistication
- Descriptiveness
- Author style analysis
- Shortest path to efficient production
- Morphological segmentation
- Automatic translation
- Alternative outcome scenarios
Purpose
ScreenJSON is there to solve specific computer-related problems, and to provide functionality not available with current authoring platforms. The data embedded in the presentation is abstracted from mark-up to objects, attributes, properties, and variable types.
- Word processors help humans to author scripts.
- PDFs help humans to publish and read scripts.
- ScreenJSON helps computer systems understand and analyze scripts.
While the normal procedure might look like:
Human author --> Authoring Program --> PDF file --> Hard Copy --> HumanA ScreenJSON document can be used is any way, e.g.
Authoring Program -->
--> JSON File (disk, HTTP)
--> PDF hard copy
--> NoSQL Database
--> Production ERP/MRP
--> Programming lang
--> Translation assets
--> Archive (+ stats)
--> Secured iPad app
--> Breakdown docs (Excel/CSV)
--> Web platform(s)
--> NLP Analysis/Predictive BotThe format is not concerned with presentation of the data, and leaves this to the host application. Implementing applications are free to manipulate, display, and the UI-specifics themselves.
The aims and objectives of defining the standard are to provide:
- A universal and database-friendly data model and object model for screenplays;
- A universal data interchange format between platforms and programs;
- Support for multi-lingual authoring;
- Methodological tagging for pre-production activities (e.g. breakdowns);
- Support for encryption and element-level access control policies;
- Support for Git-style versioning and licensing data;
- Easier access for structured batch linguistic analysis;
- Support for production/distribution technologies (e.g. 3D, etc).
Class Structure
Screenplay documents tend to focus on the visual presentation of content for printing purposes, and are generally represented in authoring programs using styled paragraphs. For example, Final Draft uses the <Paragraph> XML element, whereas Open Screenplay Format uses the <para> tag.
When looking at the data representation of the same content, the schema is a simplified document model that conforms to predictable patterns of inheritance.
Container
├── Document
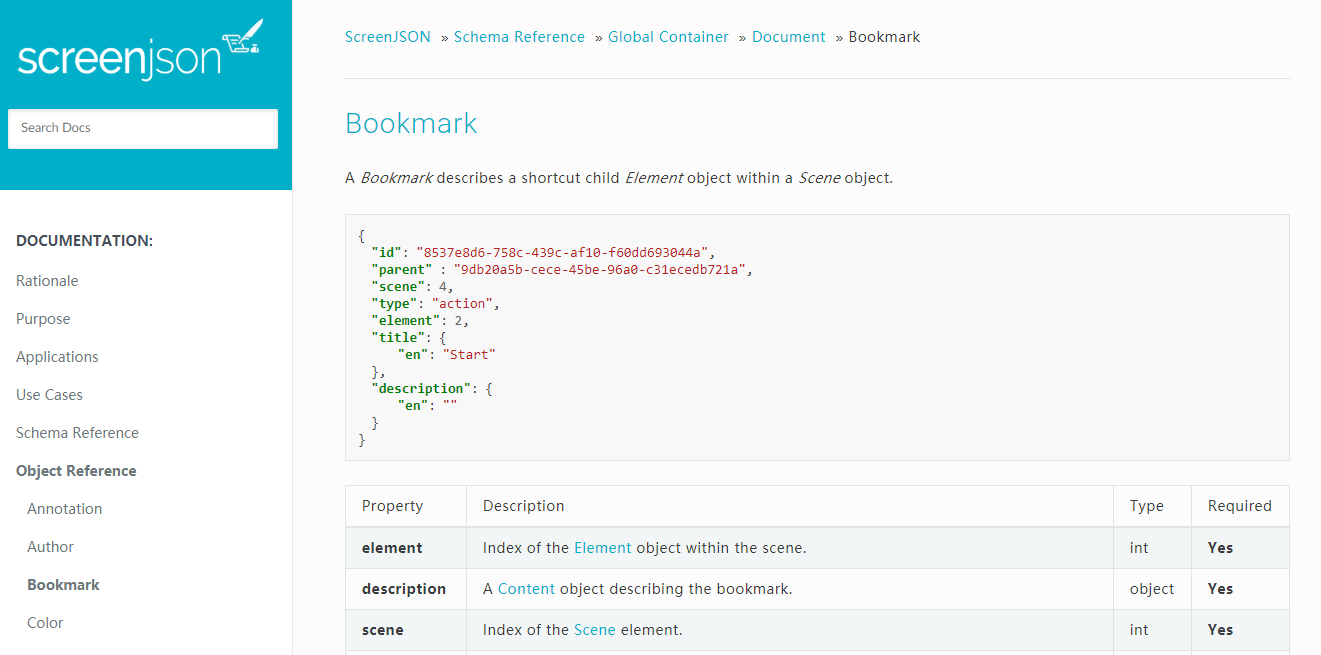
│ ├── Bookmark
│ ├── Scene
│ ├── Element
│ ├── General
│ ├── Action
│ ├── Character
│ ├── Parenthetical
│ ├── Dialogue
│ ├── Transition
│ ├── ShotA Global Container object holds the Document, which consists of a Header, Footer, Cover and additional Meta attributes, but also contains one or Annotation objects, optional Bookmark objects, and a collection of Scene objects.
A Scene object has a Heading and comprises a body sequence of one or more Element objects, such as action description, dialogue (single or dual, audio source etc), or transitions (CUT TO).
Data Formats
- Each object is given an identifier that conforms to the RFC4122 UUID specification (https://www.ietf.org/rfc/rfc4122.txt).
- Dates are represented with their timezone offsets in ISO 8601 structure (https://en.wikipedia.org/wiki/ISO_8601).
- Document licensing can be any item from the standard SPDX list (https://spdx.org/licenses/).
Example Document Object
The container Document object describes the content of the document, but leaves the presentation interpretable by the intermediary program.
{
"bookmarks" : [
{
"id": "8537e8d6-758c-439c-af10-f60dd693044a",
"parent" : "9db20a5b-cece-45be-96a0-c31ecedb721a",
"scene": 4,
"type": "action",
"element": 2,
"title": {
"en": "Third element (action) block in scene 5"
},
"description": {
"en": ""
}
}
],
"cover": {
"title" : {
"en": "THE SHAWSHANK REDEMPTION",
"es-mx": "Sueño de fuga"
},
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"meta" : {
"property": "value"
},
"derivations" : true,
"additional" : {
"en" : "Based upon the story Rita Hayworth and Shawshank Redemption by Stephen King"
}
},
"footer" : {
"cover" : true,
"display" : true,
"start": 1,
"omit" : [0],
"content" : {
"en" : "(c) __DATE__ Copyright Castle Rock Entertainment. __PAGE__"
},
"meta" : {
"property": "value"
}
},
"header" : {
"cover" : true,
"display" : true,
"start": 1,
"omit" : [0],
"content" : {
"en" : "THE SHAWSHANK REDEMPTION by Frank Darabont"
},
"meta" : {
"property": "value"
}
},
"meta": {
"created" : "2004-02-12T15:19:21+00:00",
"modified" : "2004-02-12T15:19:21+00:00"
},
"scenes" : [
],
"status" : {
"color": "blue",
"round" : 1,
"updated" : "2004-02-12T15:19:21+00:00",
"meta" : {
"property": "value"
}
},
"styles": [
{
"id" : "courier-12",
"default": true,
"content" : "font-family: courier; font-size: 12px;",
"meta" : {
"property": "value"
}
}
],
"templates": [
"default"
]
}The purpose of the Document object - other than providing a container - is to define the following information:
- Identification
- Localization
- Origin/Derivation
- Authorship
- Licensing
- Versioning
- Styling
- Metadata
- Bookmarks
- Cover
- Header
- Footer
Example Scene Object
Once the descriptive elements of the parent Document object have been defined, the actual content of the script is contained in an array of re-orderable Scene objects that are primarily numbered by their array index (overridden by numbering attribute if necessary).
The purpose of a Scene object is to define the following information:
- Setting & Context
- Ordering
- Metadata
- Pre-Production Requirements Data
The Scene Container
{
"heading": {
"numbering" : 1,
"page" : 1,
"context": {
"en" : "INT"
},
"setting": {
"en" : "CABIN"
},
"sequence": {
"en" : "NIGHT"
},
"description" : {
"en" : "Notes that appear in Card View go here."
},
"meta": {
"example": "custom property data here"
}
},
"body": [
],
"animals": ["DOG"],
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"cast": ["MAN", "WOMAN"],
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"extra": ["SKY"],
"id" : "ea20e4ea-6b35-4046-8761-b2203eb80628",
"locations": ["CABIN", "ROOM"],
"moods" : ["DARK", "EMPTY", "DRUNK", "HORNY", "URGENT", "FUMBLING", "ROUGH"],
"props": ["DOOR", "LAMP", "WINDOW", "BED"],
"sfx": ["MONSTER"],
"sounds": ["BANG"],
"tags": ["CABIN", "SEX", "INTRO", "ACT-I"],
"vfx": ["EXPLOSION"],
"wardrobe" : ["BLOUSE", "FABRIC"]
}A Scene object is comprised of Heading and array of Element objects , like a cue card (or Bootstrap panel). Each requires:
- A context (INT/EXT/POV etc)
- A setting (i.e. location)
- A sequence (DAY/NIGHT/CONTINUOUS)
Crucial to the definition of the scene are attributes for production breakdowns: moods, keywords, cast members, and other pre-prod tags useful to multiple departments, such as wardobe and props. The highlighted and/or noted capitalized elements can be manually or automatically listed for easy retrieval.
The Scene Content
The Body property of a Scene is an array of Element objects, which differ according to their type property (action, dialogue etc). Each element can be subject to customised access control policies set by the host application.
{
"body": [
{
"id": "832a4322-c2e7-4e42-b049-e6f9c821f7f0",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "action",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "Bob and Alice sit facing each other."
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"revisions": [
{
"id" : "b1fba741-4870-44fe-9b7d-234e8f0f5e5f",
"parent": "832a4322-c2e7-4e42-b049-e6f9c821f7f0",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id" : "54cad943-a74b-44b7-b4f3-c3168d57840d",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "character",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "BOB"
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"origin" : "O.C",
"revisions": [
{
"id" : "92dc6154-3a82-408d-83e6-fd4573eefbef",
"parent" : "54cad943-a74b-44b7-b4f3-c3168d57840d",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id": "dee1e326-9325-40a2-a7df-9d51dc5526ec",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "54cad943-a74b-44b7-b4f3-c3168d57840d",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "dialogue",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "Hi, Alice."
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"revisions": [
{
"id" : "eda2da50-c81b-4e93-bd79-68cd5f8fa8e1",
"parent" : "dee1e326-9325-40a2-a7df-9d51dc5526ec",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id": "81fcebe1-a2ae-4d49-91ac-b544d9a7cad6",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "character",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "ALICE"
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"dir": "ltr",
"revisions": [
{
"id" : "e024278d-cb33-4228-92d4-eb08cc180fb3",
"parent" : "81fcebe1-a2ae-4d49-91ac-b544d9a7cad6",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id" : "6e27748b-b5d9-4da5-8e53-c2766a1c074b",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "81fcebe1-a2ae-4d49-91ac-b544d9a7cad6",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "dialogue",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "Hi, Bob!"
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"revisions": [
{
"id": "c34bc1a7-fa99-4e3c-8d91-14498cdae5c0",
"parent" : "6e27748b-b5d9-4da5-8e53-c2766a1c074b",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id" : "c776c8e9-4549-4552-a68b-8bcc013c1884",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "81fcebe1-a2ae-4d49-91ac-b544d9a7cad6",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "parenthetical",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "Leaning in, smiling broadly"
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"revisions": [
{
"id" : "72194545-f6cd-44ae-b713-11067d9efaf8",
"parent" : "c776c8e9-4549-4552-a68b-8bcc013c1884",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
},
{
"id" : "9d2cd285-f523-40ca-b587-cd156a68fe6d",
"authors" : ["01979fca-6ac3-479e-9f33-d89498836eb1"],
"parent" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"type": "action",
"charset": "utf8",
"dir": "ltr",
"content": {
"en": "Bob hands her flowers."
},
"contributors" : ["8e0cd67f-f9da-46b8-98b9-16169893b439"],
"revisions": [
{
"id" : "e5acb0ed-a901-4c7e-8ee5-ee57f53ef7a9",
"parent" : "9d2cd285-f523-40ca-b587-cd156a68fe6d",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
}
]
}Any element can invoke multiple sets of styling, and accomodate language equivalents, as well as revisions and annotations (defined by their start and end character indexes in the string).
Access policies are a list of policy identifiers known to the host application, which is responsible for managing and implementing them.
An Element object has a type of:
- Action
- Character
- Dialogue
- General
- Parenthetical
- Shot
- Transition
Note: dual-dialogue is an attribute dual: true of a Dialogue element, and audio direction data (e.g. V.O, O.S) is also implemented as a class attribute.
Note: the interactivity attribute is reserved for future versions.
The purpose of an Element object is to define the following information:
- Technological implementation data (CGI, 3D etc)
- Access & UI display policy
- Multi-lingual content equivalence
- Revision-tracking & annotations
Script Content Encryption
Encryption can be applied to any JSON value — specific elements, scenes, or the entire document. Each user may have their own specific private key, or password. GUI display should auto-detect an encrypted paragraph element, and attempt to decode it with a password already stored for that user.
The beauty of this approach is that no data or handshake needs to be conducted with the back-end server. An author encrypting the element can set a password in their client program, and give it to a collaborator personally, without sending it over the wire. An author can choose to hide any number of text elements to provide different selective views for different readers.
Example client-side AES encryption with Node
In this example, we are in a Node client like Electron or Ionic. The reader GUI is able to encrypt text, or decrypt it, by providing a specified password.
We want to hide the line of dialogue from everyone except Above-The-Line, the Director, the DoP, and the actor who is going to be saying it. Everyone gets a copy of the script, but those who are not included in the access policy, or without the specific password, see a redacted block.
var crypto = require('crypto'), algorithm = 'aes-256-ctr', password = 'password_for_specific_individual';
function encrypt(text){
var cipher = crypto.createCipher(algorithm,password)
var crypted = cipher.update(text,'utf8','hex')
crypted += cipher.final('hex');
return crypted;
}
function decrypt(text){
var decipher = crypto.createDecipher(algorithm,password)
var dec = decipher.update(text,'hex','utf8')
dec += decipher.final('utf8');
return dec;
}
var dialogue_element = encrypt("I'm going to make him an offer he can't refuse.")
console.log(decrypt(dialogue_element));
Encrypted output (when using Base64, not Hex):
U2FsdGVkX19voPV6ClqPfhSFJFMEALJeZSmAVl/dukvbxtfFOondqaZLVdRg0/HxBV8g8B9iZYzYY2Aa/cH7Kw==The dialogue data element would then be expressed as:
{
"id" : "6e27748b-b5d9-4da5-8e53-c2766a1c074b",
"parent" : "81fcebe1-a2ae-4d49-91ac-b544d9a7cad6",
"scene" : "271ee0f5-8ce8-46e6-919f-87b9ace58496",
"access" : ["ABL", "director", "cinematography", "actor-corleone"],
"type": "dialogue",
"charset": "utf8",
"dir": "ltr",
"encryption" : {
"cipher" : "aes-256-ctr",
"hash" : "sha256",
"encoding" : "base64"
},
"content": {
"en": "U2FsdGVkX19voPV6ClqPfhSFJFMEALJeZSmAVl/dukvbxtfFOondqaZLVdRg0/HxBV8g8B9iZYzYY2Aa/cH7Kw=="
},
"annotations" : [
{
"highlight": [
[3,6],
[7,9]
],
"contributor": "8e0cd67f-f9da-46b8-98b9-16169893b439",
"created" : "2004-02-12T15:19:21+00:00",
"content" : {
"en" : "I can't read this. Can someone send me the password?"
},
"meta" : {
"property": "value"
}
}
],
"revisions": [
{
"id": "c34bc1a7-fa99-4e3c-8d91-14498cdae5c0",
"parent" : "6e27748b-b5d9-4da5-8e53-c2766a1c074b",
"index": 0,
"authors": [
"01979fca-6ac3-479e-9f33-d89498836eb1"
],
"version": "draft",
"created": "2004-02-12T15:19:21+00:00"
}
]
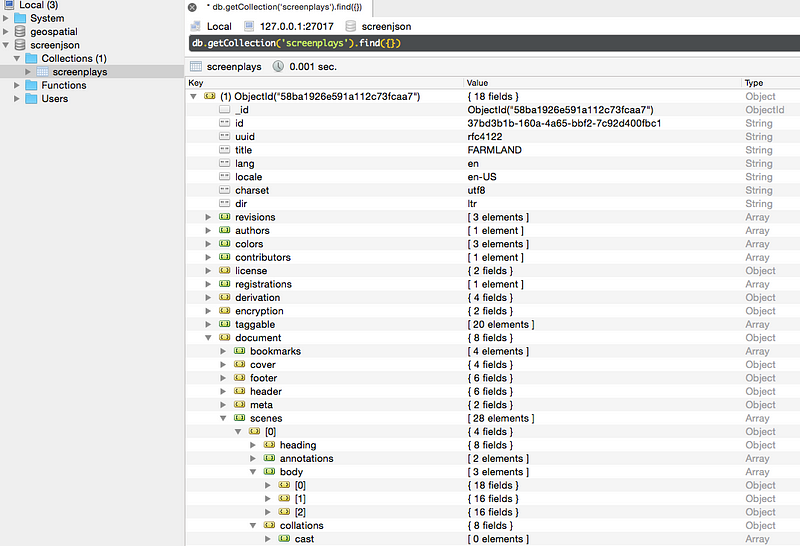
}Querying ScreenJSON screenplay documents
Once stored in a back-end NoSQL database (like MongoDB, CouchDB, Neo4j, or even HTML5 localStorage), we suddenly have a way to search the movie.
Natural Language Processing (NLP)
Definition:
Natural language processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages and, in particular, concerned with programming computers to fruitfully process large natural language corpora. Challenges in Natural Language Processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, managing human-computer dialog systems, or some combination thereof.
Syntax
- https://en.wikipedia.org/wiki/Lemmatisation
- https://en.wikipedia.org/wiki/Morphology_(linguistics)
- https://en.wikipedia.org/wiki/Part-of-speech_tagging
- https://en.wikipedia.org/wiki/Parsing
- https://en.wikipedia.org/wiki/Sentence_boundary_disambiguation
- https://en.wikipedia.org/wiki/Stemming
- https://en.wikipedia.org/wiki/Text_segmentation#Word_segmentation
Semantics
- https://en.wikipedia.org/wiki/Lexical_semantics
- https://en.wikipedia.org/wiki/Machine_translation
- https://en.wikipedia.org/wiki/Named-entity_recognition
- https://en.wikipedia.org/wiki/Natural_language_generation
- https://en.wikipedia.org/wiki/Natural_language_understanding
- https://en.wikipedia.org/wiki/Optical_character_recognition
- https://en.wikipedia.org/wiki/Question_answering
- https://en.wikipedia.org/wiki/Textual_entailment
- https://en.wikipedia.org/wiki/Relationship_extraction
- https://en.wikipedia.org/wiki/Sentiment_analysis
- https://en.wikipedia.org/wiki/Topic_segmentation
- https://en.wikipedia.org/wiki/Word_sense_disambiguation
Discourse
- https://en.wikipedia.org/wiki/Automatic_summarization
- https://en.wikipedia.org/wiki/Coreference
- https://en.wikipedia.org/wiki/Discourse_analysis
Screenplay Processing Research Papers
- “Classifying Movie Scripts by Genre with a MEMM Using NLP-Based Features”(Alex Blackstock, Matt Spitz)
- “SceneMaker: Automatic Visualisation of Screenplays” (Eva Hanser, Paul Mc Kevitt, Tom Lunney, Joan Condell)
- “Speaker identification from film dialogues” (Kundu, A., Das, D., & Bandyopadhyay, S.)
- “Predicting Box Office from the Screenplay: An Empirical Model” (Starling David Hunter, Susan Smith, Saba Singh)
- “Exploiting Structure and Conventions of Movie Scripts for Information Retrieval and Text Mining” (Jhala, A)
- “Scene Boundary Detection from Movie Dialogue: A Genetic Algorithm Approach”(Amitava Kundu, Dipankar Das, Sivaji Bandyopadhyay)
- “Early prediction of a film’s box office success using natural language processing techniques and machine learning” (Sean O’Driscoll)
- “From Storyline to Box Office: A New Approach for Green-Lighting Movie Scripts”(Eliashberg, Hui and Zhang)
- “An Annotated Corpus of Film Dialogue for Learning and Characterizing Character Style” (Walker, M. A., Lin)
- “Gender-Distinguishing Features in Film Dialogue” (Alexandra Schofield, Leo Mehr, CLFL 2016)
- “Assessing Box Office Performance Using Movie Scripts: A Kernel-based Approach”(Jehoshua Eliashberg, Sam K. Hui, Z. John Zhang)
- “Pre-production forecasting of movie revenues with a dynamic artificial neural network” (M. Ghiassi, David Lio, Brian Moon)
- “Parsing Screenplays for Extracting Social Networks from Movies” ( Agarwal, A., Balasubramanian, S., Zheng, J., & Dash, S)
ScreenJSON is available on Github under a Attribution-ShareAlike (CC BY-SA) Creative Commons license, for anyone to use freely.
https://screenjson.com