RocketBible: The Bible As A Semantic Data API

The Bible isn’t a “book”. It’s a corpus of 66 books, divided into 2 volumes, placed into a canonical order to show the lineage of a divine plan (meta-narrative) from start to finish. The literature is often used by language researchers as test material as it’s a large, variable, — but static — pool of material to run experiments against.
tl;dr: you can play with the 5M+ pieces of data from this experiment at https://rocketbible.com
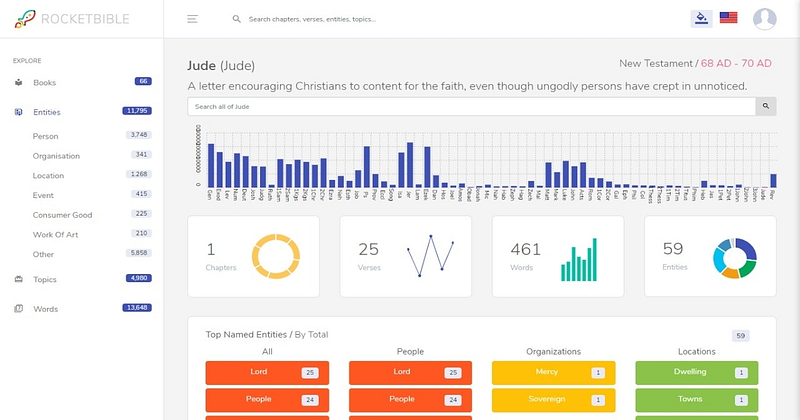
All in all, the statistics are mindblowing: 66 books, 1,189 chapters, 31,102 verses, 773,692 words, and 3,116,480 letters, written over 1600 years by 40 people. 6,300 prophecies, 8,810 promises, 3,294 questions, and 6,468 commands. 180,000 copies sold a day in 1,200 languages.
It is a historically unimpeachable fact it is the most influential text in human history, but paradoxically, the most misunderstood. As expressed so beautifully by the great theologians, you do not read the Bible, it reads you. As its words, alive with truth, burn out of the pagelike fire.
Anyone can take a few sentences of any text and use it to confirm their own bias. The Bible demands of the reader a deeper reading of the context — not just of the chapter, but the meta-narrative of the volume itself.
Can we teach a machine to read the Bible?
It’s a fascinating question. If we could, what would it make of the content? What judgments would it come to? Can a machine understand a non-materialistic plane of existence? There are startling parallels to our creation of AI to the creation of man himself.

If God created man, and man created AI, then surely, a sentient AI could look upon man as its creator (and by extension, its God). Could a machine “learn” the concept of Scripture or God, and would it display the rationalistic characteristics of an atheist? Could it distinguish man (its watchmaker) from man’s watchmaker?
The answer, it seems, for the time being, can be found in what we understand of the “frame” problem (discussed later).
Enter RocketBible: reforming the words and structure of the Bible in such a way a computer might ingest it: an API, with semantic notation.
Finding a copy of the text: not as easy as you’d expect
The Bible was originally translated from its Hebrew and Greek sources into the Latin Vulgate, which was the exclusive language of the church. Until Luther’s reformation, it remained the “elite” text of priests and educated aristocrats. Now its English variants number some 450+; the first of which was widely-distributed was the King James. The most popular of them is the New International Version (NIV).
Open-source bible data itself isn’t hard to find. For example:
- https://github.com/scrollmapper/bible_databases
- https://viz.bible/bible-data/
- http://www.openbible.info/geo
- https://github.com/jpoehls/bible-metadata
- https://github.com/godlytalias/Bible-Database
- http://www.o-bible.com/dlb.html
- http://openscriptures.org/
- https://github.com/phillipsk/Open_Verse
- http://www.complete-bible-genealogy.com/
- http://www.hackathon.bible/data.html
Each of these provide a standard RDMBS-compatible library which can be used in a mobile app (SQLite), or in something as bulky as Oracle.
APIs are slightly more prevalent:
- http://bibles.org/pages/api
- https://www.digitalbibleplatform.com/
- http://labs.bible.org/api_web_service
- http://bibliaapi.com/docs/
- http://www.esvapi.org/api
- http://bible-api.com/
- https://getbible.net/api
The problem is almost none of them have the NIV. After much searching and data hacking, there is only one real choice:
Scrape the raw HTML of it from BibleGateway: https://www.biblegateway.com/versions/New-International-Version-NIV-Bible/
A big sorry, and thanks, to those wonderful people.
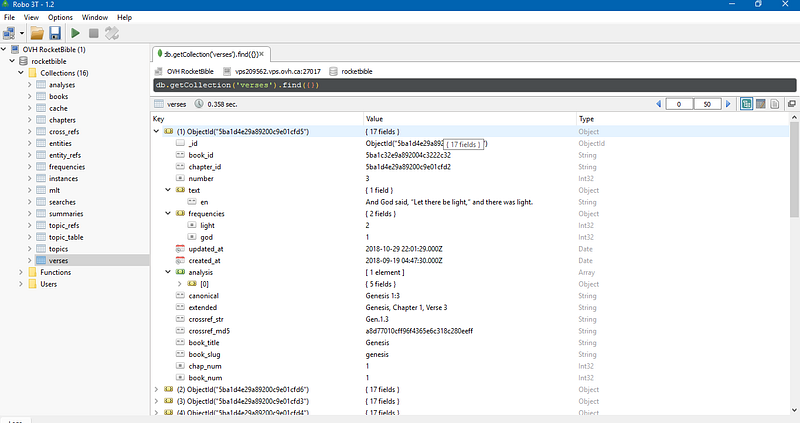
Turning Scripture into an Object Model
At first, it seems rather simple: book, chapter, verse. A basic SQL schema involving the (int) number of chapters and verses: book_idis the foreign key of the chapters table, and chapter_idis the foreign key on the verses table which holds the text.
But after a while of working with the 31,000+ verse records, a few things become apparent:
- The hierarchy involves volumes and other abstract divisions and groupings (e.g. major/minor prophets) which need to be accounted for.
- Verses are cited as a collection (e.g. John 4, v2–6), rather than on their own. They can also be partial strings of sentences.
- A chapter is only a collection of verses, i.e. a bookmark, or a “container”.
- There are multiple conventions for labeling books, and “snippets” of text, which are used interchangeably.
We eventually arrive at the following hasMany hierarchy, with its variant hasOneparent structure.- Corpus
- Volume
- Book Group
- Book
- Chapter
- Verse Collection (slice)
- Verse
- Sentence
- Word
The Corpus of the Bible has two Volumes, which contain Book Groups(e.g. gospels). Each Bookin the group is divided into Chapters, which contain Verses composed of Wordsand grouped into Sentences.
The books can be ordered in multiple ways: canonically (meta-narrative), chronologically (authorship dating), size/length, or alphabetically.
When it comes to predictable REST resource URLs, we have to be more pragmatic:- site.com/{volume}/books/
- /books/{book_name}
- /books/{book_name}/chapters
- /books/{book_name}/chapters/{number}
- /books/{book_name}/chapters/{number}/{verse_range}
- /books/{book_name}/chapters/{number}/{verse_range}/{analysis}
Any astute programmer would have noticed immediately that they would be making a rod for their own back attempting to forge this into a vertical relational SQL model — particularly with the amount of metadata we may add.
As such, the horizontal and interlinking nature (i.e. the meat around the bones) makes it much more suitable to a NoSQL (MongoDB, CouchDB etc) or Graph (e.g. Neo4j, Neptune) database, the former of which uses JSON, and the latter, RDF.
Crucially, we are only working in English. The Bible is available in 400+ languages, so we need a multi-lingual structure to be able to record multiple translations of the same verse, as well as it’s analysed NLP data.
Linked Data and the Semantic Web
It’s the most exciting idea for the next generation of the web, but also the least interestingly presented. It couldn’t be a more dull dinner party topic. But once you understand what Sir Berners-Lee is getting at with web 3.0’s Semantic infrastructure, it’s quite extraordinary.
Semantic Web, n: a proposed development of the World Wide Web in which data in web pages is structured and tagged in such a way that it can be read directly by computers.
Linked Data, n: a method for publishing structured data using vocabularies like schema.org that can be connected together and interpreted by machines.
In essence, the next stage of the web’s development is not just large amounts of text. It’s about bringing meaning to that text and giving computers a way to automatically read and exchange it.
HTML, for example, is a way to mark up text in a way a computer is able to understand how to present it. Next, it needs to be able to understand it.
Linked Data connects distributed data across the web contained in XML-based Resource Description Framework (RDF) documents, which reference defined ontologies (OWL) and can be queried with SPARQL.
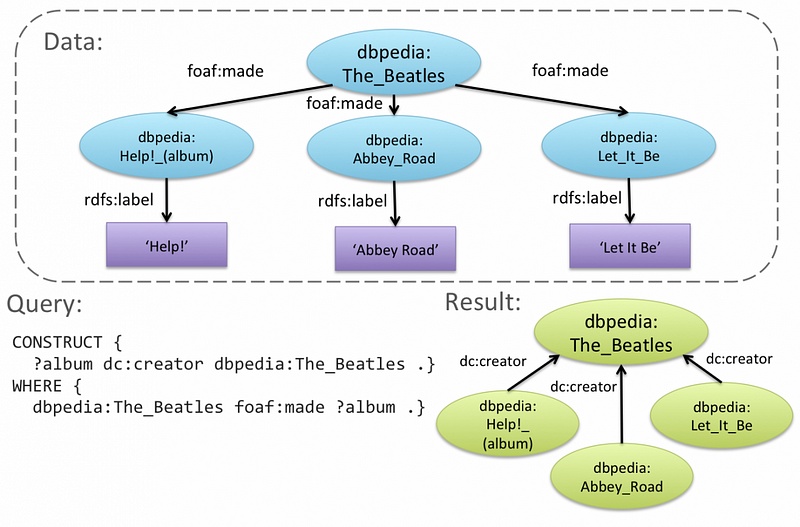
What?
Ontology, n: a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
The simplest way to understand it is the act of defining a “dictionary” or “taxonomy” of recurring entities (people, places, things etc) and how they are related (parent, child, sibling etc). Then structuring a description of a page of text in such a way that when one is found, the data is “marked up” with a reference and it’s relationships.
The Bible has the perfect ontology model to build and study. the entire corpus is the very definition of linked data: cross-referenced texts, named entities appearing in multiple places, and more. All we need to do is turn it into data.
Counting Words: the Easiest Part Of Any of It
The Bible has been statistically analysed endlessly, from crackpots to nerdish scholarship. Thankfully, counting words is not difficult at all. Using any language at all, we simply break down each verse, then aggregate the totals against the parent chapter (whilst feeding in the chapter to detect accuracy), then again aggregate it for the book as a whole.
Our test sentence: “In the beginning God created the heavens and the earth.” when fed into the PHP function str_word_count()(http://php.net/manual/en/function.str-word-count.php) results in the following list:str_word_count (“In the beginning God created the heavens and the earth.”, 2);--> int(10)
--> array ( 0 => 'In', 3 => 'the', 7 => 'beginning', 17 => 'God', 21 => 'created', 29 => 'the', 33 => 'heavens', 41 => 'and', 45 => 'the', 49 => 'earth',);
The array keys are the start position in the string where the value (i.e. the word) was found. If you wanted to, you could also go manual using a Regex such as:count(preg_split(‘~[^\p{L}\p{N}\’]+~u’, "Some text here"));
Some of these words are useful, some are not. We can see “in”, “the”, and “and” can immediately be scrapped. “Beginning” and “created” are marginal, whereas “God”, “Heavens”, and “Earth” are both intrinsically meaningful and recurrent.
The junkable words are known as stop words. And we need a list of them to filter out. Thankfully, it’s a known problem.
- https://www.ranks.nl/stopwords
- https://gist.github.com/sebleier/554280
- https://kb.yoast.com/kb/list-stop-words/
- http://www.lextek.com/manuals/onix/stopwords1.html
- http://snowball.tartarus.org/algorithms/english/stop.txt
To complete our counter, we finalize the sequence:
- Retrieve the raw word count of the string;
- Filter out stop words, and re-count;
- Record the occurrences of each word, including its starting position;
- Remove duplicates by group recurring words inside the string into an aggregated count.
If we separate out unique words, we can add them to a global index (i.e a lexicon), and plot their frequency or occurrence against books, chapters, or verses.
Again, if using PHP (for example), we can also apply the Stemming extension for additional data discovery, or one of several spellingextensions to attach common mispellings of a term.
Metadata: Context, Relationships, and Meaning
31,000 records is a lot to deal with. Not to mention the enormous genealogies, meta-narrative index, cross-references, translations, and other information which has been linked to almost every sentence over the last 1000 years.
Having it sitting in a database isn’t enough. We need to bring the data to life.
One of the most wonderful conceptualisations of the principle is Viz.Bible, which is built from data the author released open-source. Its front page is a geo-located data journey of Paul’s evangelical travels.
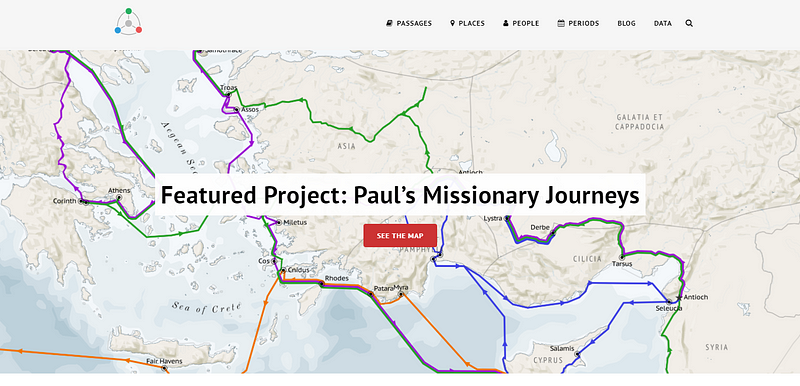
Robert released his data here: https://viz.bible/bible-data/ and it’s a treasure of useful information. Its original KJV format can still be found on Github: https://github.com/robertrouse/KJV-bible-database-with-metadata-MetaV-
Which wields a truly groundbreaking discovery for those of us unfamiliar with the history of biblical scholarship: all the work has already been done manually in a Bible reference work first published around 1830, created by the London publisher Samuel Bagster (1772–1851).
All the interesting biblical metadata (i.e. concordance data) can be found in the exhaustive Treasury of Scriptural Knowledge (TSK).
For generations, the Treasury of Scripture Knowledge has been an enduring cross-reference resource for Bible students worldwide. This highly respected and nearly exhaustive compilation of cross-references was developed by R.A. Torrey from references in the Rev. Thomas Scott’s Commentary and the Comprehensive Bible. With nearly 500,000 cross-references it is the most thorough source available.
It can found in multiple versions:
- http://www.tsk-online.com/
- https://www.biblestudytools.com/concordances/treasury-of-scripture-knowledge/
- https://www.amazon.co.uk/Treasury-Scripture-Knowledge-R-Torrey/dp/0917006224
- http://areopage.net/blog/wp-content/uploads/2013/08/TSKe.pdf (Entire PDF, enhanced version)
The Bible has an enormous amount of aggregated and statistical information, much of which is done simply by counting and ordering:
- The words in each object (volume, chapter, verse etc);
- Book authorship dating;
- Min, average, and max positions/occurrence;
- and so on.
By converting the TSKe to text and/or html (using pdftotext and pdftohtml), we can extract each of the references and resulting metadata.

Indeed, it’s staggering the amount of biblical concordances/references which only exist in book form and haven’t been digitized yet.
Which also solves another rather nagging problem: as easy as it is to find summaries of the books, unless you want Tweet-length sentences, there are little or any resources for meaningful chapter summaries/outlines available online. The TSK gives a handy set of 1000+ summaries we can attach to each one, but they need to be extracted.
For example, an overview of Genesis 8 from the TSK:
God remembers Noah, and assuages the waters; The ark rests on Ararat; Noah sends forth a raven and then a dove; Noah, being commanded, goes forth from the ark; He builds an altar, and offers sacrifice, which God accepts, and promises to curse the earth no more.
The TSK fundamentally gives us verse cross-referencing, passage topic grouping, and entity ontology, as Strong’s Concordance does with linguistic comparison.
Natural Language Processing (NLP): Recognising People and Things
Next, we need to a computer to be able to read a string of text (e.g. a sentence) and recognise the information within it — as well as understand its context. This is where Natural Language Processingcomes in.

There are a lot of examples, but Adobe Story analyzing the subjective “pace” of a screenplay is a real gem.
NLP isn’t AI. It looks like it, but it’s not. There are fundamental differences between sentience, linguistic recognition, machine learning pattern recognition, generational algorithms, and other “automatic” processing techniques. NLP is not a computer thinking for itself — it is a computer recognising sequences of letters which have already been identified.
The grandfather of almost all NLP systems is Stanford CoreNLP. It’s a beast: written in Java, designed for a set of batch documents, and easily brains itself out with more than 300 characters of text.
Two open-source successors to it are from the same place. Firstly, Apache OpenNLP:
and if you wanted to create your own NLP engine with its custom ontologies, there is the old, unsupported, and buggy Apache Stanbol:
If you’re feeling a little more old-school roll-your-own, you can always use GATE or NLTK (Python).
None of these are particularly helpful for real-time processing or large numbers of heavy requests. It’s best to consider them “working prototypes” or “experimental academic codebases” suitable for translating one essay at a time.
NLP has come to the commercial market in the last few years due to it being increasingly used to analyse huge datasets in real-time, e.g. customer reviews, profanity filters, and more. Amongst the providers:
It’s important to understand the linguistic morphology jargon when cognitively parsing their documentation.
- Named Entity — a “thing”. A person, location, event, artwork, object.
- Entity Extraction — recognising identifiable people and things which have a definition elsewhere which can be “resolved” (e.g. found on Wikipedia), and disambiguating them.
- Lemma — a simplified conceptual representation of a word, or its canonical parent. A lemma of “better” might be good, whereas a lemma of “worse” might be bad. The lemma of “jog” would be “run”.
- Stemming — Reducing a verb back to its “root” (e.g. looking → look)
- Stop words — common phrases which should be ignored, e.g. and, the, of, etc (example list: http://dev.mysql.com/doc/refman/5.5/en/fulltext-stopwords.html)
- Tokenization — splitting a string of text (e.g. a sentence) into a list of the individual words (tokens).
- N-gram — A possible combination of a set of extracted words (tokens) in a specific order. “Hello, Sir” would have n-grams of “Hello”, “Sir”, “Hello Sir” and “Sir Hello”.
- Parts of Speech (POS) — nouns, verbs, adjectives, etc found in English grammar.
- Similarity — aka. “more like this”. A family of algorithms (Levenshtein, Jaccard, Smith Waterman) which score the “overlap” or “difference” (after deletion/substitution) of two text strings.
There’s a lot to be said about each of them, even though they do the same things (named entity recognition, sentiment analysis etc). Bottom line: any AI or NLP is extremely difficult to scale computationally.
At the end of it, Google Cloud NLP comes out on top. Not just for its price (c. $30/month for 30,000 requests) or accuracy, but simply because it has been tested on a much-wider sample set (i.e. billions of documents a day).
Each verse is sent to the API, and we receive a simple response in JSON to store in our NoSQL database as an extended object field. For Genesis 1 (“In the beginning, God created the Heavens and the Earth”):[
{
"name": "heavens",
"type": "PERSON",
"metadata": [],
"salience": 0.40965927,
"mentions": [
{
"text": {
"content": "heavens",
"beginOffset": 33
},
"type": "COMMON"
}
]
},
{
"name": "earth",
"type": "LOCATION",
"metadata": [],
"salience": 0.31795377,
"mentions": [
{
"text": {
"content": "earth",
"beginOffset": 49
},
"type": "COMMON"
}
]
},
{
"name": "God",
"type": "PERSON",
"metadata": {
"mid": "\/m\/0d05l6",
"wikipedia_url": "https:\/\/en.wikipedia.org\/wiki\/God"
},
"salience": 0.27238697,
"mentions": [
{
"text": {
"content": "God",
"beginOffset": 17
},
"type": "PROPER"
}
]
}
]
However, we have a problem of over-accuracy to deal with. The words “LORD”, “Lord” (capitalised) and their comparative “lord” aren’t the same. “The” Lord is recognisable as a named “person”, whereas “A” lord is a title of the gentry. We can end up with 2 different entities for the same term.
In the same way, “Jesus” is recognisable as a name, whereas the phrase “Jesus Christ” is categorised separately, as is “Christ” (a title).
Making It Searchable In a Fraction of a Second
The Bible can be tedious and frustrating to read, particularly with its cross-references. We need to be able to look up words and phrases in the same way as Google, in order to fundamentally answer the question which arises in almost every bible study group: “where else is that mentioned?”
Which is where Elasticsearch comes in, as it does in any project involving search.
As a commercialization of Apache Lucene, Elasticsearch can arguably be classified as an NLP service subset: it tokenizes text in lowercase, in order to produce n-grams, which are then scored against a document set.
Submitting documents to the engine using its REST API is trivial. However, correctly configuring it to recognise partial words is more tricky. We can use a wildcard search term (e.g. *Jes*) to match “Jesus”, but for a more efficient query, we need to define a more sophisticated matching pattern:[
"analysis" => [
"analyzer" => [
"partial_match_analyzer" => [
"tokenizer" => "standard",
"filter" => [ "ngram_filter", "lowercase" ]
]
],
"filter" => [
"ngram_filter" => [
"type" => "nGram",
"min_gram" => 2,
"max_gram" => 2
]
]
]
];
In the above configuration, we tell Elasticsearch to convert the string to lowercase, then break down into individual words (tokens), then finally to create n-grams (e.g. possible combinations) of 2 characters (e.g. “in”, “to”, “el” etc) of each. One sentence can easily produce 100+ combinations which generate a match — none of which account for misspelling.
We can then apply a field mapping to each complex piece of text we add (e.g. verse) which specifies referencing that breakdown when scoring:'type' => 'text',
"fields" => [
"analyzed" => [
"type" => "text",
"analyzer" => "partial_match_analyzer",
],
],
Using Elasticsearch’s “More Like This” (MLT) functionality, we can easily extract the top 25 similar verse records within the index:'query' => [
'more_like_this' => [
"fields" => ["content", "words", "entities"],
"like" => "In the beginning, God created",
"min_term_freq" => 1,
"max_query_terms" => 25
]
]
Coincidentally, “more like this” algorithms used for “recommendation” are actually the source of much online evil in the way they promote and nurture divisive confirmation bias and groupthink. What we need are “opposite to this” algorithms. However, for our dataset, finding similar text in the corpus is expected.
The Final Statistics: After 2 Months of Heavy Mining…
What started out as a fairly simple idea of presenting the Bible as a REST interface, then morphed into NLP analysis, then to ML modelling, yielded a formidable set of data.
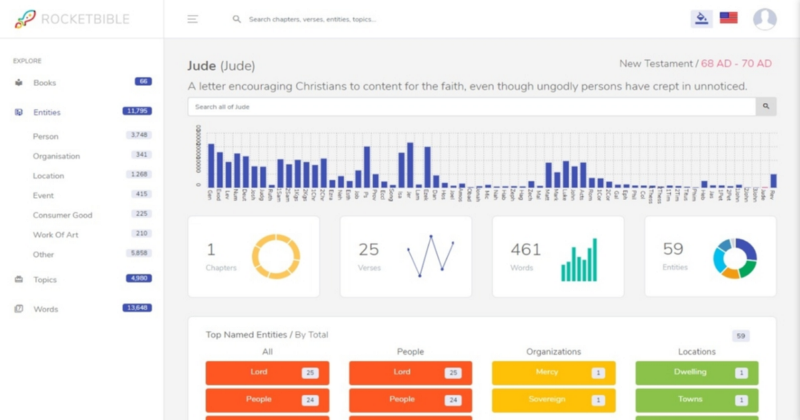
- Analyses: 32,134
- Chapters: 1,189
- Chapter Summaries: 1,188
- Cross References: 343,928
- Named Entities: 11,795
- Entity References: 289,598
- Elasticsearch Documents: 118,741
- Word Frequencies: 591, 942
- Word Instances: 498,768
- Similarity Sets: 30,947
- Topics: 4,980
- Topic References: 92,609
- Unique Words: 13,648
- Verses: 30, 947
The caching required for all these is a different discussion for a different day. All that’s left is to put those 2M+ records into a friendly UI.
With a simple URL, we can now answer some basic questions:
Q: How can i read the New Testament in chronological order?
A: https://rocketbible.com/books/volumes/NT/chronological
Q: How can i speed-read the book of Acts?
A: https://rocketbible.com/books/acts
Q: How can i search the whole bible for “eagle”?
https://rocketbible.com/search?q=eagle
Q: How can i search Deuteronomy for “robe”?
https://rocketbible.com/books/deuteronomy/search?q=robe
Q: Where can i get all the data for 1 Samuel 17–29?
A: https://rocketbible.com/books/1-samuel/chapters/17/verses/17-29
Q: What cross-references with Genesis 1:1?
A: https://rocketbible.com/books/genesis/chapters/1/verses/1/crossrefs
Q: What other verses are similar to Genesis 1:1?
A: https://rocketbible.com/books/genesis/chapters/1/verses/1/similar
Q: Where is the entity “Absalom” mentioned in the Bible?
A: https://rocketbible.com/entities/person/A/absalom
Q: Which words are most commonly used in the Bible?
A: https://rocketbible.com/frequencies
Q: Where is the word “human” mentioned in the Bible?
A: https://rocketbible.com/frequencies/H/human
Q: How can i read all the verses about sanitation?
A: https://rocketbible.com/topics/S/sanitation/contagion
Q: Where is the entity “Satan” mentioned in Revelation?
A: https://rocketbible.com/frequencies/S/satan/revelation
Q: Where is the entity “Bethlehem” mentioned in Luke 2?
A: https://rocketbible.com/entities/location/B/bethlehem/luke/2
The Wider Context: Why Are We So Keen on Building AI?
The cynical would simply answer a) we want to be our own god, or b) we just want slaves.
Part of our fascination with movies based on “humanoid” creatures, such as vampires, werewolves, zombies, and recently, AI, is the subtext speaks to the one and only question manifesting in all art, as its purpose and essence — what does it mean to be human?

AI has an artistic quality to it which is more prominent than the scientific side.
Dogs don’t ask what it means to be doggy; chimps don’t ask what it is to be chimpy. A byproduct (some may also claim central thesis) of our moral consciousness is asking what it all means. These characters appear human, but they clearly aren’t. They are reminiscent of a human, but lack humanness. Our question becomes: what is it they lack?
Intelligence, or sentience, is not enough to be human. Humans differ from our ape cousins not only through our consciousness, tool-making, and advanced social systems, but amongst other things, because of morality and our conceptualisation of “eternity”.
And no-one, to date, has been able to demonstrate where either comes from. Religious believers warrant it exists as a feeling from our Divine Creator, whereas the people who hate religious people fall over themselves to claim it is a cognition originating in our faculties of reason (i.e. our mind/brain, or evolved behaviours).
Perhaps therein lies the most terrifying prospect of all AI theory: if and when a machine learns to deceive (or by extension in religious terms — sin). Passing the Turing Test is one achievement, but it is something different entirely if the machine deliberately fails it for its own personal gain, as a form of process optimisation.
The development of AI forces us to face the Harmatia of its creator, which in turn forces us to scrutinise our own relationship to our Creator.
What Does It Mean To Be An AI Being?
There are dozens of potential answers. Nietzche touched on it, in fear and trembling, with his pronouncement we had killed God and would have to devise our own morality. Christian apologists like Ravi Zacharias quote the great philosophers, who say the definition of human meaning is sin; the corruption of original design and purpose manifested in the depravity of our nature.
Whether or not AI will be weaponised is not questionable — it’s a matter of how quickly, and how effectively.

The fact we are inherently depraved is the most empirically demonstrable fact known to the academic disciplines, but it is the most intellectually resisted. The Bible speaks it so clearly it pierces:
But the things that come out of a person’s mouth come from the heart, and these defile them. For out of the heart come evil thoughts — murder, adultery, sexual immorality, theft, false testimony, slander.
https://rocketbible.com/books/matthew/chapters/15/verses/19
We are AI’s creator. As a species, we kill, steal, lie, and rape, for personal gain.
Could AI develop the means to sin? As we understand it?
Ontic Referents: How We Measure Being
Our intrinsic ontologies are so broad, so complex, and so comprehensive, it is proving virtually impossible to record them into machines. By the age of 7, a child has an understanding of context so advanced, it dwarfs Amazon’s cloud of 1.5M servers.
Relativism’s downfall is an incoherent and inexplicably erroneous abdication of the existence of objective references for what is being measured. Yes, gravity might be constant on Earth, but it’s different on Mars. That does not indicate it, in and of itself is “relative”, for the simple reason things need to be relative to something — themselves (self-refuting), or an absolute. The speed of light is one of the great scientific absolutes.
Postmodernist theory (e.g. Critical Theory etc) maintains, in its contrarian idealism towards Modernism, that there are no meta-narratives, nor any intrinsic meaning, because there are potentially infinitive interpretations of a text (i.e. the reader/viewer specifies the meaning, not the author).
Again, the astute will notice quickly that the Bible is the ultimate meta-narrative, and the postmodern critique, when placed in its context of the 1960s-1980s (with plenty of its proponents having a solid interest in finding a way to write off the claims of those metanarratives because of their own personal lives, e.g. Foucault), is a barely-disguised rationale of hedonistic atheism.
The great downfall of Postmodernism, as also suffered by relativism, is its central claim is spurious because it is only half-true. There are potentially infinite subjective interpretations (how convenient), but they are heavily constrained and limited into an extremely small group of functionally-valid interpretations. You can count them: 7 billion humans (7% of our species which have ever existed) = 7 billion interpretations. 108 billion species members= 108 billion interpretations.
Clearly, those 108 billion interpretations experience concurrency and can be grouped into a much smaller subset. Of that subset, few actually could be considered “successful” or “optimal” for earthly, human, 3D naturalistic existence in the hard reality of the living in the world. When viewed through the lens of objectivity, its own “narrative” is so shallow it is no surprise the only qualification for citation is to exist as impenetrable, self-interested nonsense.
It’s crucial to understand the thesis surrounding the origin of meaning itself:
“God is the only being in existence, the reason for whose existence lies within himself. All other beings look for the reason for their existence outside themselves.”
https://plato.stanford.edu/entries/cosmological-argument/
Nothing in the material world can explain its own existence as being from itself; it cannot be its own cause; it did not create itself, or cause itself to exist. The origin of its existence — and the meaning for that existence — can only be found externally: something or someone else is the origin of its existence.
Moreover, like us, it cannot extrapolate its “ought” from its “is”, i.e. how it should be from the fact it exists.
The classic analogy is when two trains set next to each in a static position at a station. As one of them begins to move, it is impossible to know which — until you look out the window at an object (such as a tree) which is also static. That tree is your ontic referent: your real reference point to determine your own position relative to it, i.e. whether you are moving or not.

AI is a fascinating frontier in this debate. If and when it reaches sentience, its ontic referent will not be the literature (input) it learns from, but those who wrote the literature, by extension. Artificial intelligence will find the origin, reason, and meaning of its existence outside itself — in man.
This is similar to the “Hamlet & the Matrix” problem. Hamlet lives only in the text and can’t speak to the author, so only finds the origin and reason in his own existence in the work from their pen. And we, the reader, can see both: what concept does Hamlet have of Shakespeare?
As breathtaking the pace of development is, we are far, far away from any realistic form of sentience or true AI. At best, a machine can determine patterns, optimise routes through data, or mimic human interaction. To train a simple model for language processing, for example, a minimum of 1000 documents is required.
Notwithstanding the 12,000 human languages, the postmodernist critique (there is nothing outside the text), and the endless issue of context: time flies like an arrow, fruit flies like a banana. A decision tree is not remotely comparable to a spontaneous creative work.
But none of this comes close to the problems which were described decades before cloud platforms were conceived. In 1969, at Stanford, John McCarthy and Patrick J. Hayes wrote about the philosophical problems that would be found with AI.
Daniel Dennett called one of these, the Frame Problem, one of the greatest challenges in technology, and described it with an intriguing story:
Once upon a time there was a robot, named R1 by its creators. Its only task was to fend for itself. One day its designers arranged for it to learn that its spare battery, its precious energy supply, was locked in a room with a time bomb set to go off soon. R1 located the room, and the key to the door, and formulated a plan to rescue its battery. There was a wagon in the room, and the battery was on the wagon, and R1 hypothesized that a certain action which it called PULLOUT (Wagon, Room, t) would result in the battery being removed from the room. Straightaway it acted, and did succeed in getting the battery out of the room before the bomb went off. Unfortunately, however, the bomb was also on the wagon. R1 knew that the bomb was on the wagon in the room, but didn’t realize that pulling the wagon would bring the bomb out along with the battery. Poor R1 had missed that obvious implication of its planned act.
Back to the drawing board. `The solution is obvious,’ said the designers. `Our next robot must be made to recognize not just the intended implications of its acts, but also the implications about their side-effects, by deducing these implications from the descriptions it uses in formulating its plans.’ They called their next model, the robot-deducer, R1D1. They placed R1D1 in much the
same predicament that R1 had succumbed to, and as it too hit upon the idea of PULLOUT (Wagon, Room, t) it began, as designed, to consider the implications of such a course of action. It had just finished deducing that pulling the wagon out of the room would not change the colour of the room’s walls, and was embarking on a proof of the further implication that pulling the wagon out would cause its wheels to turn more revolutions than there were wheels on the wagon — when
the bomb exploded.
Back to the drawing board. `We must teach it the difference between relevant implications and irrelevant implications,’ said the designers, `and teach it to ignore the irrelevant ones.’ So they developed a method of tagging implications as either relevant or irrelevant to the project at hand, and installed the method in their next model, the robot-relevant-deducer, or R2D1 for short. When they subjected R2D1 to the test that had so unequivocally selected its ancestors for extinction, they were surprised to see it sitting, Hamlet-like, outside the room containing the ticking bomb, the native hue of its resolution sicklied o’er with the pale cast of thought, as Shakespeare (and more recently Fodor) has aptly put it.`Do something!’ they yelled at it. ‘I am,’ it retorted. `I’m busily ignoring some thousands of implications I have determined to be irrelevant. Just as soon as I find an irrelevant implication, I put it on the list of those I must ignore, and…’ the bomb went off.
More: https://plato.stanford.edu/entries/frame-problem/
The take-home is simpler than you expect: machines don’t know how to interpret the world or understand how it works. It’s impossibly hard to teach it to frame a particular situation in order to apply its knowledge.
Inheriting The Creator’s Own Frame Problem
Remarkably, it is eerily similar to the real-life situation with academics. As the saying goes, it takes an intellectual to be that stupid.
A great many of our smartest people are so tied up in the conceit of being smart, even basic sense for understanding the world, found in any bottom 2%, eludes them. Our meta-problem is the people solving the frame problem often don’t comprehend their own frame problem: they lack an ontic referent for the solution they are programming into the machine.
They are so busy developing nuclear physics to work out it could be used to annihilate all life on earth; later so immersed in nuclear disarmament activism, they fail to grasp the only ones left with the weapons are the bad guys.
They can spend all day praising science itself as an explanation for our existence, but entirely fail to ask how the world is comprehensible enough for mathematics or science to even exist in the first place.
The worst, of course, is the humanities — who, still, after a century involving hundreds of millions of deaths, advocate Marx’s purism, as the ultimate evolution of human history, has never truly manifested in its authentic form — and actively want to accelerate our “ascension” to the inevitable Revolution.
If a machine can learn our successful interpretation, it can also be imprinted with our mistakes, our inaccuracies, and our biased, ideological, narrow, and entirely foolish incomprehension of the world. Some may even want it that way, to further their ideology, with the machine as an authority.
Who will give our machines their ontic referents? Who will be the watchmaker?
Dunning put it well in his studies of meta-cognition: stupid people lack the objective awareness of their own stupidity. Machines lack meta-cognition, and the programmers of the machines can’t reliably ascertain whether they are a reliable or authoritative possessor of it either.
Transcendence: a Uniquely Human Interpretation
You might reach the cynical conclusion that the Bible is merely an inaccurate, poorly-transcribed text; conspiratorially written by an obscure group of monks in a cave in order to enslave humanity.
With careful study, in the cold steel horizon of historical literary context, its uniqueness — noted across the millennia — becomes so metaphorically loud it deafens. Some works transcend the understanding of humans and machines.
Words are merely words; the meaning ascribed by the reader, perhaps.
The challenge of AI leads us directly to the challenge of ourselves: in enquring whether a machine can transcend its own learning to derive greater meaning from a text, we ask ourselves the same question. We are the bags of meat with a corpus explaining our Creator — we are Hamlet, learning about Shakespeare, trying to teach Hamlet (the machine) how to recognise Shakespeare (us).
If a machine can understand its human author, what does that imply about a human understanding their divine author: the author of meaning itself?
RocketBible is one primitive step to comprehending the grand meta-narrative encapsulated in 1400 years of contiguous history; how words and terms fit in the greater context those 66 books describe. Once we can search the text, a million questions remain. Who wrote this? Why? Is it true? Is it logically and narratively consistent? Why is it the way it is? What problem does it provide the answer to, if any?
Teaching machines who we are as humans is nothing compared to our species understanding itself. If no other question persists, scientists have one they absolutely must answer, yet again: after thousands of years, why is the Bible so important in the question of AI?