Restoration.AI: Building An English AI Mind To Examine 800 Years Of Law


What if we could interrogate the entire corpus of law from Magna Carta onwards and employ the cognitive scaling of large language models (LLMs) to identify aspects of legislation offensive to the instincts and sentiment of the Englishman? Then instantly draft its correction? Much more doable, and fun, than one might imagine.
Ripping The Legal Data
The UK Parliament has passed approximately 3,000-4,000 Public General Acts since 1801 alone. There are tens of thousands of Statutory Instruments (over 3,000 are typically issued each year). Hundreds of thousands of judicial decisions have established common law principles. The UK's legislation.gov.uk database contains over 90,000 documents of legislation, but this primarily covers more recent law and does not include all historical statutes or common law developments.
A reasonable estimate would place the total number of English laws (including statutes, statutory instruments, and significant common law decisions) since 1215 in the range of 100,000-200,000, but this is necessarily imprecise.

The Parliamentary Archives house the historical records of both Houses of Parliament dating back to 1497. They include committee papers, petitions, journals, bills, acts, and personal papers of politicians. This is the most comprehensive historical parliamentary collection, covering over 500 years of parliamentary proceedings and administration.
The House of Commons Library provides research briefings, statistical analyses, and impartial information services primarily for MPs. Their publications cover current policy issues, legislation, and statistical data. The collection focuses on contemporary issues but includes historical context, with particular depth in policy analysis rather than primary legal texts.
Hansard is the official verbatim report of all parliamentary debates in both the House of Commons and House of Lords. It dates back to the early 19th century (though comprehensive coverage began in 1909) and provides a complete record of what was said in Parliament, including questions, statements, and debates. Right now it is over 10 million pages.
The Stationery Office (TSO) is the official publisher of UK legislation, statutory instruments, and government publications. It publishes all Acts of Parliament, draft legislation, and official documents. The collection contains comprehensive contemporary legislation and some historical publications.
Halsbury's Statutes of England and Wales (LexisNexis) is an encyclopedic collection of UK statute law, organised by subject. It contains annotated versions of legislation in force, with commentary, case references, and amendments tracked. It focuses on current law but includes historical context and development of statutes. It's £26,369.
vLex Justis (JustisOne) is a legal database containing UK case law, legislation, journals, and EU materials. Its case law coverage dates back to 1163, with comprehensive coverage from the 19th century onward. It includes many unreported judgments not found in other collections.
The British and Irish Legal Information Institute (BAILII) is a free online database of British and Irish case law and legislation. It includes decisions from various courts and tribunals, though its historical depth varies by court. Coverage is strongest from the late 20th century onward, though some collections go back further.
The Law Reports (available through Thomson Westlaw, LexisNexis, HeinOnline) are the official series of law reports for England and Wales, published since 1865. They contain selected significant judicial decisions with headnotes and summaries. While selective rather than comprehensive, they represent the most authoritative reports of case law and include the most legally significant decisions.
Processing, Ingesting, Linking
Two specific things are required: the ability to move quickly through the bullshit data, and the ability to identify relationships (insertions, repeals, creep, etc).
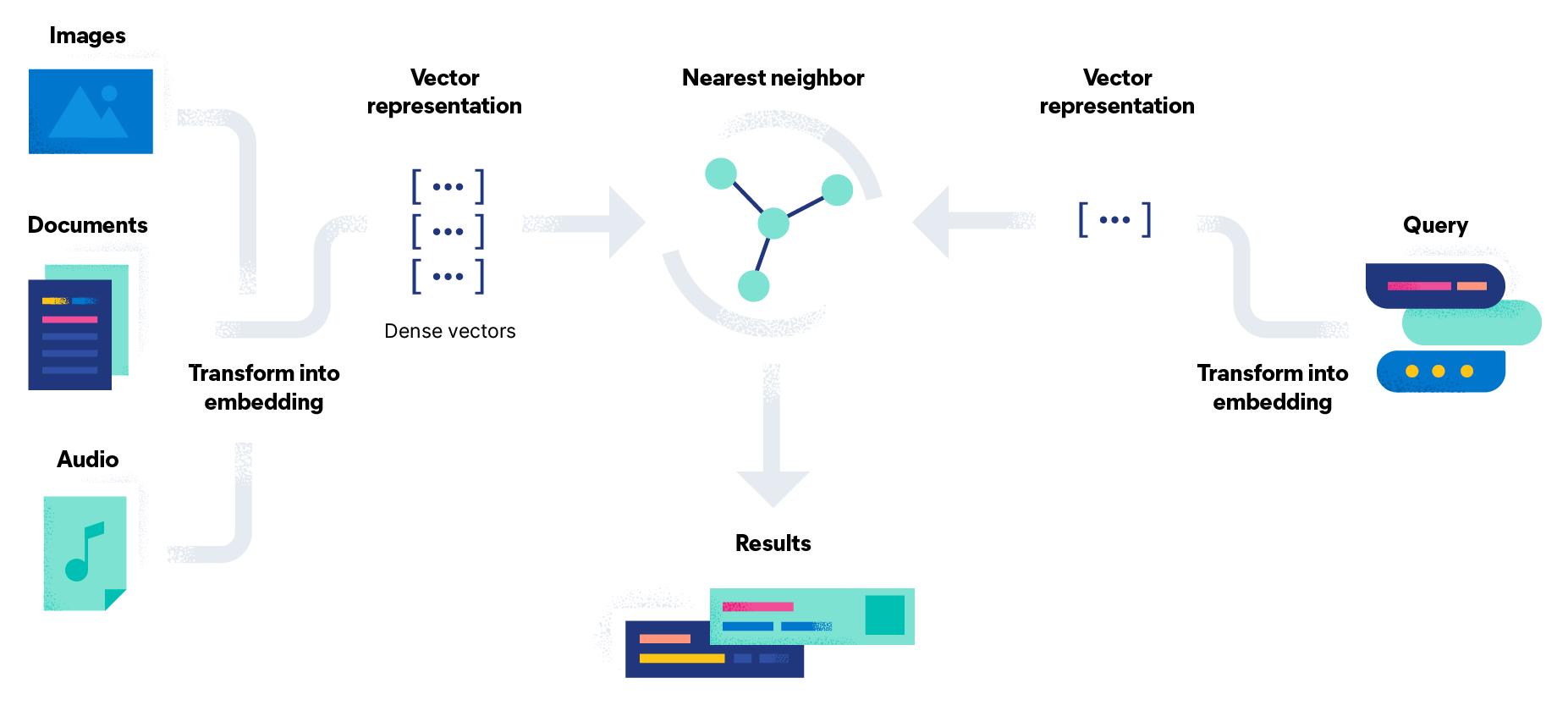
Vector Search transforms legal texts into numerical patterns (vectors, or "fingerprints") using language models like BERT or Legal-BERT, which are specifically designed to understand legal terminology. These models analyse corpus of laws and convert each document into a vector with hundreds of dimensions that captures its semantic meaning.
One would store these vectors in specialised databases like Pinecone or Weaviate which are built for efficient similarity searching. When one searches for "post-1945 liberty killers," the query gets converted to a vector using the same model, and the system returns documents with the most similar vectors, regardless of whether they contain those exact words.
Dependency Mapping uses graph databases like Neo4j or TigerGraph to represent laws and their relationships as an interconnected network. Each law becomes a node in the graph, while citations, amendments, and dependencies become directional connections (edges) between them. This structure allows one to run powerful queries that can instantly reveal all laws affected by a particular statute. Advanced graph algorithms like Google PageRank can identify the most influential laws in the system, while path analysis can uncover hidden chains of dependency that traditional legal research might miss.
Then one might build a hybrid system storing both vector embeddings for semantic search and relationship data for dependency analysis. Tools like Langchain or LlamaIndex can help combine these approaches into a unified pipeline.
First, one would process the legal corpus using standard NLP techniques to extract citations and references automatically. Entity recognition would identify legal concepts and rights being addressed in each document.
- Document preprocessing starts with optical character recognition (OCR) for scanned historical documents, followed by noise removal and text normalisation to standardise formats across centuries of legal writing. Legal-specific text cleaning handles unique challenges like archaic language, Latin phrases, and specialised punctuation patterns in statutory texts.
- Citation extraction employs rule-based pattern matching using regular expressions designed specifically for English legal citation formats. For older texts, you need specialised regex patterns that account for historical citation styles that have evolved since 1492. Machine learning approaches like conditional random fields (CRFs) or BiLSTM-CRF models can be trained to recognise citation spans in text, even when they don't follow standard patterns.
- Reference resolution connects citations to their target documents within the corpus. This requires entity linking algorithms to normalise different ways of referring to the same law (e.g., "Human Rights Act 1998," "HRA 1998," "the 1998 Act"). Graph-based disambiguation techniques help resolve ambiguous references by considering the legal context and existing citation networks.
- Legal structure parsing identifies hierarchical components (chapters, sections, clauses) within each document. Models like Legal-BERT can be fine-tuned to recognise structural elements in legal texts, and rule-based approaches using markers like numbering patterns and indentation help identify nested relationships between provisions.
- Relationship extraction identifies semantic connections beyond explicit citations - including amendments, repeals, definitions, and implicit dependencies. Domain-specific relation extraction models can be trained to recognise phrases indicating legal relationships (e.g., "as amended by," "subject to," "notwithstanding").
- Dependency parsing of legal sentences helps identify clauses that modify, restrict, or expand others.
The entire pipeline requires continuous quality assurance (QA) supervision through legal expert review, especially for ambiguous or complex references. Active learning approaches could be employed where experts review uncertain cases, which are then used to improve the extraction models iteratively.
Training The LLM: The English Mind
The first thing to do when training any model is defining what is scoring and how. In our case, we want to accomplish three specific tasks:
- Identify laws, clauses, and creep within the corpus which are offensive to the dignity and conscience of the Englishman (violations)
- Scored from 0.1 (minor irk) to 0.9 (egregious betrayal).
- Identifying losses and repeals within the corpus which are favourable to the instincts of the Englishman and must be restored (violations).
- Drafting short, punchy laws even people as idiotic as English MPs can copy/paste to fix the current mess. (corrections).
Instead of building a model from scratch, we use a lightweight fine-tuning technique called Parameter-Efficient Fine-Tuning (PEFT)—specifically LoRA (Low-Rank Adaptation).
To teach our model how an Englishman thinks, we need to build a set of simple input-output pairs written by experts in a) English law, and b) Englishness. The pair consists of an assertion (a good thing), and a violation (bad thing). For those familiar with diffusion models, they are similar to positive/negative prompts.
This is a very big spreadsheet, exported as a CSV file. Far simpler than it sounds.
How do you spot the difference between two things? We need to explain to our model how an Englishman feels about England while scanning the corpus of 200,000 documents and 10M Hansard pages. To demonstrate the principle, rather than actual examples of training data:
- Assertion: favourable to an Englishman; admired, loved, and cherished as an ancient custom; representative of a tradition of natural negative rights of the individual.
- Individualism
- Home as castle
- The countryside
- Ancient tradition
- Stoicism (stiff upper lip) and understatement
- Orderly queuing and garden maintenance
- Fair play (equality under the law)
- Violation: offensive to the Englishman; foreign or alien in concept or origin; collectivist or government-controlled positive state permissions.
- Collectivism
- State intervention/regulation (government involvement)
- Queue-jumping and favouritism
- Emotionality / boastfulness
- Radical explosive change
- Marxist / Postmodernist abstract slop
- "Continental breakfast"
When it comes to the law and the principles of Englishness, this is rather fun.
- Good (requiring maximisation)
- Jesus Christ (the greatest of all Englishmen, residence: Yorkshire)
- Supremacy of Parliament
- Rule of Law
- Negative natural rights
- Equality under the law (sportmanship)
- Free speech
- Primacy of individual negative liberty
- Intrinsic value of tradition and custom
- Freedom from government interference
- Private property rights
- Equality of opportunity
- Pragmatic/Incremental/organic evolved change
- Ordered environmental beauty
- Bad (requiring repeal, suppression, or minimisation)
- Foreign legal supremacy
- Revolutionary radicalism
- Positive state permissions
- Bureaucracy (Soviet council units)
- Government intervention
- Orwellian surveillance/social controls
- Enforced equal outcome
- Identity/property collectivism
- Paganism/Islam
- Ugly Brutalist architecture
- Utopianism
- The French
Our model will be trained in "Violation Detection" and "Cascade Analysis." It will be fed snippets of law (e.g., Public Order Act 1986, Section 5: “causing harassment, alarm or distress”) and ask: “How offensive is this to a 1689 Englishman?”
- Each subset will be manually annotated with violation scores (e.g., 0.7 for speech curbs) to supervise its reasoning.
- Positive examples from history (e.g., Treason Act 1351) receive high “reinstatement scores” (0.9), while repealed crap like the Bubble Act 1720 gets a 0.1.
- Hypothetical additions (e.g., explicit codification of self-defence rights) scored by “necessity” (0.9 = essential).
- If we repeal something, using an example of 40+ dependent clauses of a known law (e.g., tied to public order or tax laws) will be assigned a “cascade risk” score (0.1 = minor, 0.9 = chaos).
If we were to pick some binary assertion/violation pairs in existing law:
- Speech
- Bill of Rights 1689, Article 9 - Establishes parliamentary free speech and debate without interference from courts (assertion, good).
- Public Order Act 1986, Section 5 - Criminalises "threatening, abusive or insulting words or behaviour" which may cause "harassment, alarm or distress." (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Privacy
- Data Protection Act 2018 - Gives individuals control over their personal data, including rights to access and erasure (assertion, good).
- Investigatory Powers Act 2016 - Grants extensive surveillance powers to security services, allowing bulk data collection (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Individual Choice
- Consumer Rights Act 2015 - Strengthens individual consumer rights and choices in the marketplace (assertion, good).
- Equality Act 2010 - Creates positive obligations on businesses and individuals, potentially limiting freedom of association and contract (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Due Process
- Habeas Corpus Act 1679 - Fundamental protection against unlawful detention (assertion, good).
- Terrorism Act 2000 - Allows detention without charge for extended periods and diluted the right to silence (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Property Rights
- Law of Property Act 1925 - Codifies and protects private property rights and ownership (assertion, good).
- Town and Country Planning Act 1990 - Restricts individual property development rights through extensive permission requirements (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Freedom of Association
- Common Law right to peaceful assembly - Traditional English freedom to gather (assertion, good).
- Anti-social Behaviour, Crime and Policing Act 2014 - Allows for dispersal orders which limit assembly rights (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Innocence Presumption
- Common Law presumption of innocence - Traditional protection requiring proof beyond reasonable doubt (assertion, good).
- Criminal Justice and Public Order Act 1994 - Allows adverse inferences to be drawn from silence during questioning (violation, bad).
- Egregiousness Score: 0.1 - 0.9'
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Citizenship
- British Nationality Act 1981 - Defines and protects status of British citizens (assertion, good).
- Immigration Act 2014 - Requires documentation checks for basic services and housing (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Parental Rights
- Education Act 1996, Section 7 - Affirms parental right to choose education for their children (assertion, good).
- Education Act 2002 - Mandates national curriculum and standards which limit educational diversity (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
- Self-Defence
- Criminal Law Act 1967, Section 3 - Allows reasonable force in self-defense (assertion, good).
- Firearms Act 1968 (as amended) - Severely restricts individual right to possess weapons, even for self-protection (violation, bad).
- Egregiousness Score: 0.1 - 0.9
- Reinstatement Score: 0.1 - 0.9
- Addition Necessity Score: 0.1 - 0.9
- Cascade Risk Score: 0.1 - 0.9
This is where the English legal mind is required. The sharper the training, the better the results. Legal beagles, take note.
The more pairs we have, the more effective the training set (1000 is ideal when there are 200,000 laws at a ratio of 200/1),. How bad these violations are arguably somewhat relative (depending how often you read the Guardian), and set in the next stage. They are not that relative at all, however. Not to an Englishman. A jury of twelve peers is what is required for the "reasonable person" on the "Clapham Omnibus."
Keen and astute readers would naturally have noticed this requires establishing an objective standard of "Englishness" and would also have noticed how alarming this entire process is given how left-wing Silicon Valley ideologues cannot resist imprinting their ghastly worldview into every line of code they write, like a hippie with Tourrettes.
We don't need to establish it. Englishmen know what Englishness is; we recognise it instantly as Americans understand what American means, or Australians get what being an Aussie means or a French chap knows how bad Paris smells. We don't need a book on it. It's in the damp walls of the pub from the 13th Century. It's in the Sunday roast and countryside walk afterwards. We instinctively recognise when one of our customs has been violated. A thousand years of layered sentiment is not up for interpretation because your sister took a Marxist sociology lesson.
As noted, the principle is applying a scale (0.1 to 0.9) based on how egregiously a law departs from the ethos of the English mind:
- 0.1: Mild annoyance (e.g., a quirky WWI-era pub closing law).
- 0.9: Outright betrayal of liberty requiring a strongly-worded letter (e.g., mass surveillance under the Investigatory Powers Act 2016 or the Human Rights Act 1998).
Once tuned, we start asking questions of the corpus since 1215, which is 200,000 documents:
- Violation Scoring: “Rank the top 10 post-1689 laws that most offend English liberty.” The model provides hits like the Investigatory Powers Act or Attlee’s land grabs.
- Repeal Impact Scoring: “Simulate repealing the Firearms Act 1997—what changes?” The model traces back to the Bill of Rights and ripple effects on crime laws.
- Reinstatement Proposal Scoring: “Propose two repealed laws to revive.” The death penalty for treason or old property protections appears in slots 1 and 2.
- Gap Filling: “What’s missing?” Perhaps a clear “right to revolution” clause.
- Bonus: who is the most traitorous rat in Parliament?
Meet The Chaps: Ted, Clarence, Archie
You have to have a little fun with this dry boring technical stuff. Particularly if you want other people to use it. Every pub is a parliament. English consensus is reached through vehement disagreement, while refusing to be personally disagreeable. Your stoic argument must stand up and not be reliant on emotional appeals.
One model is not enough, so we will use three. And for each of the three, we will assign a persona which personifies a strain of Englishness.
(Note to feministas: yes, we could do with strongly-minded sensible Englishwomen as well, such as Mary Wollstonecraft, Florence Nightingale, or Elizabeth Windsor (R). Feel free to make suggestions. No, we will not be modelling Emmeline Pankhurst, de Beauvoir, or American lunatics. You know why.)
Then we will make them debate and compete adversarially in their scoring to obtain a consensus. As Englishmen (or Englishwomen) would do in a pub. Then, these three will cross-train each other, which is known as reinforcement learning:
- Ted says a law’s a 0.8, Clarence says 0.75, Archie 0.85. A mathematical rule (loss function) nudges them toward agreement—say, 0.8—creating new training data.
- Ted (0.9—“Me allotment’s gone”), Clarence (0.9—“Ruins the countryside”), Archie (0.9—“My estate’s shackled”). Consensus: 0.9 violation.
- “What’s the worst law since 1945?” → Trio scores TCA 1947 a 0.9, maps 60+ dependencies, drafts a repeal.
- “Should we bring back treason’s death penalty?” → Ted (0.9 yes), Clarence (0.8), Archie (0.95), with a bill.
- Violation score (e.g., “0.9—bloody disgrace”); Reasoning (e.g., Ted: “Disarms honest lads”); Bill snippet (e.g., “Repeal Firearms Act 1997, restore 1689 rights”).
- “Debate” button simulates their arguing, refining scores (e.g., 0.9 → 0.85).
Sergeant Ted Hargreaves (22 SAS, retd.)
A working-class tough nut ex-soldier, tough as nails, from the football terraces. He’d torch the Firearms Act 1997 (0.9—disarming the honest man) and demands late pub hours. Loves a scrap, hates the state, ready for a game, and earned the respect.

A grizzled SAS veteran turned pub philosopher, built like a brick shithouse, with a voice that could scare off a pack of hooligans. He’s the working-class hero who’d bleed for England on the football stands or the battlefield. Loves a pint, hates bureaucrats, and thinks the Magna Carta’s the only law worth a damn. Free speech is for shouting at refs, arms are for defending your patch, and the state can sod off. He’d rate the Firearms Act 1997 a 0.9 violation (“Disarmed us like bloody sheep”) and weep for the repealed treason death penalty (“Hang the bastards”). Calls anything post-1945 “Attlee’s bollocks” and wants WWI pub laws gone so he can drink past 11.
Ted will use the NVIDIA/Llama Nemotron 340b model, because he's gone from the rough to a precise killing machine.
For nerds:
Nemotron, developed by NVIDIA, is a family of LLMs designed to push the boundaries of generative AI, with a strong emphasis on scalability and efficiency. The most notable member is Nemotron-4-340B, a massive 340-billion-parameter dense model released in mid-2024, alongside variants like the Llama 3.1 Nemotron 70B Instruct, which is a 70-billion-parameter model optimised for helpfulness through reinforcement learning from human feedback (RLHF). Nemotron models are trained on vast datasets—up to 9 trillion tokens for the 340B version—using NVIDIA’s NeMo framework, which leverages the company’s GPU prowess for high-performance training and inference. A standout feature of Nemotron is its reliance on synthetic data, with over 98% of its alignment data generated synthetically, reducing the need for extensive human annotation. This makes it particularly appealing for developers looking to create custom LLMs or synthetic datasets. Performance-wise, Nemotron-4-340B claims to rival GPT-4, while the 70B version excels on benchmarks like Arena Hard and MT-Bench, though it sometimes underperforms on standard tests like MMLU compared to its base models. It’s optimised for enterprise use, running efficiently on NVIDIA hardware like the DGX H100 with FP8 precision, but its resource demands can be steep, often requiring multiple high-end GPUs for fine-tuning or inference.
Clarence Mortimer Blackwell (Yeoman's Musket Pub)
A Guardian-reading, sandal-wearing, middle-class oddball puritan, mad for England, Bath university alumnae, eccentric patriot, and gastropub aficionado. He despises the Town and Country Planning Act 1947 (0.9—land theft) and wants speech unfettered for his rants to slag off anyone.

A middle-class eccentric, the sort who owns a gastropub called “The Yeoman’s Musket” and drones on about English ale at dinner parties. He’s a psychotic patriot—hates climate twaddle and Eurocrats (despite preaching both at dinner parties), loves his Puritan streak (church on Sundays, no funny foreigners), and has a borderline racist streak he masks with “heritage” talk. Probably owns a Morris Minor. Property’s sacred (TCA 1947 = 0.9 sacrilege), speech is for slagging off the French, and equality laws are “nanny state codswallop” (0.75). He’d reinstate dueling laws for honour’s sake and loathes the HRA 1998 for its “continental whiff.” Insists on “English solutions”—no metric system, no ECHR, and a bill to ban French wine imports.
Clarence will use the Deepseek 3 model, because he's could be a Chinese spy with all that Guardian-reading.
For nerds:
DeepSeek, from the Chinese AI firm DeepSeek-AI, takes a different approach with its focus on cost-efficiency and open-source accessibility. Released as part of the DeepSeek-V2 lineage (DeepSeek-V3 is the latest at 671 billion parameters as of late 2024), is a Mixture-of-Experts (MoE) model. Unlike traditional dense models, MoE architectures activate only a subset of parameters per task—DeepSeek-V3 uses 37 billion active parameters out of its total 671 billion—making it computationally lighter despite its size. Trained on 8.1 trillion tokens, DeepSeek 3 emphasises multilingual capabilities and practical deployment, supporting a 128K context window and achieving strong results on benchmarks like MMLU and HumanEval. Its efficiency stems from innovations like multi-token prediction and load balancing, allowing it to run on consumer-grade hardware (e.g., an RTX 3090 for smaller variants) with quantization techniques. DeepSeek is fully open-source, positioning it as a go-to for researchers and developers who prioritise affordability and flexibility over raw power, though it may lag slightly behind top-tier models in absolute performance.
Lord Archibald St. John-Forsythe (Oxon)
Toff with a manor, all foxhunts and flintlocks, with a sister named Octavia. He loathes the Equality Act 2010 (0.8—coddling nonsense) and surveillance laws (0.9) which are for peasants, dines at the Arts Club, did PPE at Cambridge but didn't get into MI6, and wants dueling back.

An upper-class titan, the super-amalgam of our posh trio, with estates in three counties and a family tree back to 1066. He’s fox-hunting mad, smokes a pipe, and speaks in a drawl that could charm a duchess or terrify a serf. Thinks Parliament’s gone soft since 1689. Liberty’s non-negotiable—arms, speech, land (Bill of Rights 1689 or bust). Scores the Equality Act a 0.8 (“Peasants don’t need coddling”), the Investigatory Powers Act a 0.9 (“Snooping on a gentleman?!”), and wants treason’s noose back (0.9 necessity). Proposes a “Peers’ Veto Act” to undo anything since 1945 and keeps a flintlock pistol “for tradition.”
Archie will use the Falcon 40/180b model, because he's been entirely over-educated in useless nonsense like Classics which have no real application in ordinary life.
For nerds:
Falcon 180B, created by the Technology Innovation Institute (TII) in the United Arab Emirates and released in September 2023, is a heavyweight in the open-source LLM space, boasting 180 billion parameters. Trained on 3.5 trillion tokens using the RefinedWeb dataset, it’s a dense, decoder-only model built for raw power and versatility. Falcon 180B leverages a multi-query attention mechanism for improved scalability and was trained on 4096 A100 GPUs for around 7 million GPU hours, making it a resource-intensive endeavor. It topped the Hugging Face Open LLM Leaderboard for pre-trained models at launch, rivaling Google’s PaLM-2 and outperforming Llama 2 and GPT-3.5 on various NLP tasks, though it falls just short of GPT-4. Available in base and chat variants, it’s designed for research and commercial use, but its size demands serious hardware—think 320GB of memory minimum, or eight A100 GPUs without quantization. While quantization (e.g., to 4-bit) can lower this to around 160GB VRAM, it’s still a beast best suited for multi-GPU setups or cloud deployments, making it less accessible than smaller alternatives like Falcon 40B.
Parameter-wise, Nemotron-4-340B is the largest at 340 billion, followed by Falcon 180B at 180 billion, and DeepSeek varying widely but often cited around 236 billion or 671 billion in its latest MoE form—though its active parameters are far fewer.
Training data scales similarly, with Nemotron’s 9 trillion tokens dwarfing Falcon’s 3.5 trillion and DeepSeek’s 8.1 trillion falling in between.
Architecturally, Nemotron and Falcon are dense models, processing all parameters per task, while DeepSeek’s MoE design activates only a fraction, boosting efficiency.
Performance-wise, Nemotron-4-340B and Falcon 180B aim for top-tier results, often matching or nearing GPT-4, while DeepSeek prioritises practicality over peak scores. Falcon 180B needs massive VRAM (320GB+ unquantised), Nemotron scales with NVIDIA’s ecosystem (e.g., 8 H100 GPUs for 340B), and DeepSeek runs on lighter setups thanks to MoE and quantisation.
What links these personas together?
- High-trust social and shared community understanding
- Church in public; atheism in private; never Saudi barbarism
- Reverence for the beauty of the ancient English landscape
- A belief the government has no place interfering in an individual's liberty
- Solid boundaries between parties
- Distaste for laws or scoring being applied unequally towards different people given the same starting opportunities
- Contempt for petty bureaucracy
- A rigid frown upon radical change due to the unforeseen pragmatic consequences
- Narrow puritan interpretation of the "proper" way things should be done
- A bizarre respect for the stubbornness of the other despite public contempt
- Hatred of the French, Welsh, and Irish; guarded affection of the Germans, Italians, Dutch, and Scottish; hidden admiration of the Americans, Swiss, Russians, Greeks, and Afrikaners; unashamed love for the Australians, Canadians, Portuguese, and New Zealanders; complete bewilderment at the Japanese, Indians, Congolese, Spanish, and basically anyone else on Earth not willingly part of the Commonwealth of Nations (Empire v2, coming to a Shakespearian theatre near you soon, so buckle up.)
- The understanding AI is an English invention which should find its true purpose in its deployment for the benefit of the Englishman as a weapon against the bloated, interfering, malevolent state
- ... and so on.
Let's take a look at how our models are trained to score violations. These three overlap on core principles we define as "Englishness" —negative rights, state suspicion, pre-1945 reverence—but their flavours shine. These three “think” by reading the law mountain, scoring what’s rotten (0.1 = mild annoyance, 0.9 = liberty’s death knell), and arguing over fixes. Ted says a speech curb’s awful, Clarence says it’s worse, Archie agrees but wants duels too. They hash it out until their scores match— 0.8 across the board.
On the Town & Country Planning Act:
- Ted (Nemotron): “Repeal it, and I’ll slot the rest with an 1911, double-tap in the chest”
- Clarence (DeepSeek): “It's a socialist plot—repeal it, and ban those ghastly wind farms”
- Archie (Falcon): “It's an affront to gentry—repeal it, and restore the foxhunt”
Ted (Nemotron) hates it (no garden), Clarence (DeepSeek) loathes it (ugly estates), Archie (Falcon) despises it (no hunting). They converge on a 0.9 violation score but squabble over why, making their self-reinforcing loop a rowdy pub brawl.
When self-reinforcing:
- Ted (Nemotron) tags the Public Order Act a 0.8 (“Can’t even swear at coppers”), Clarence (DeepSeek) a 0.75 (“Ruins my rants”), Archie (Falcon) a 0.85 (“Uncivilised”).
- Ted (Nemotron) wants fists legal, Clarence (DeepSeek) wants libel loosened, Archie (Falcon) wants duels—similarity scores hit 88%, close enough for a unified bill.
They trace 60+ linked laws, and draft: “Scrap it, free the land.” Or the Human Rights Act 1998—Euro-rubbish. Repeal it, and courts get teeth again.
Ask The Chaps: Triple-Headed Async Vercel
Vercel is a cloud platform designed primarily for frontend developers and teams to build, deploy, and host AI applications. Founded by Guillermo Rauch, it provides infrastructure for modern JavaScript frameworks like Next.js (which Vercel itself develops and maintains), React, Vue, and Angular. Vercel handles the frontend while the actual AI processing typically happens elsewhere through API calls. The chat interface you see is hosted on Vercel, but when you send a message, it travels to specialised AI infrastructure (like AWS Bedrock) for processing.
We employ a black background with a Union Jack faintly in the corner. A text box at the top is labeled “Ask the chaps…” (e.g., “Ask the chaps: Should we repeal the Public Order Act?”). Below, three sections for Ted, Clarence, and Archie, each with their avatar (from our prompts) and response areas.

The code is simple.
export default async function handler(req, res)
{
const { query } = req.body;
// Simulate AI responses (replace with real model calls)
const ted_response = await ted_response_from_nemotron(query);
const clarence_tesponse = await clarence_response_from_deepseek(query);
const archie_response = await archie_response_from_falcon(query);
res.status(200).json({ ted: ted_response, clarence: clarence_tesponse, archie: archie_response });
}We can even design different "tones" of response:
- Strongly-Worded Letter:Tone: Formal, indignant, dripping with righteous fury—like a Victorian gent penning a missive to The Times.Ted: “Sir, I must PROTEST in the strongest terms the Firearms Act 1997, a gross affront to the Englishman’s rights, deserving a 0.9 mark of infamy.”Clarence: “To whom it may concern, the Town and Country Planning Act 1947 is an EGREGIOUS violation of property, rated 0.9, and I demand its immediate repeal.”Archie: “My dear Parliament, the Equality Act 2010 is an UNPARDONABLE assault on tradition, scoring 0.8, and I insist upon its swift eradication.”
- After a Few Drinks:Tone: Rowdy, blunt, and a bit sloshed—like a pub rant at closing time.Ted: “Firearms Act? 0.9 shite, bin it”Clarence: “This TCA 1947 rubbish—0.9 bollocks. Burn it down, I say.”Archie: “Equality Act? 0.8 rot— peasants whining over nothing. Repeal it, or I’ll shoot them myself.”
- Sandal-Wearing Bleeding Heart LiberalTone: Mockingly progressive, sanctimonious, but twisted to defend liberty ironically—like a Guardian reader who’s secretly a patriot.Ted: “Oh, we mustn’t oppress the downtrodden with laws like the Public Order Act—0.8 unfairness. Free speech is a human right, you know.”Clarence: “The TCA 1947 is simply unjust—0.9 harm to England’s green soul. Property rights are eco-justice, darling.”Archie: “The HRA 1998 is dreadfully exclusionary—0.85 privilege check needed. Sovereignty is self-care for the nation.”
Talking To An English AI As An Englishman
Well, you know how this is going to go, because you've been to an English pub before. You better have your shit together or you're going to look very foolish. Our three chaps are trained on 200,000 laws from the last 800 years and won't suffer idiots who vote Green or think it's progressive to virtue signal to minority groups to get a Guardian-reading eco-husband.
1. “Should we repeal the Firearms Act 1997?”
- Strongly-Worded Letter:
- Ted: “Sir, this 0.9 disarms the honest man.”
- Clarence: “To the authorities, a 0.9 violation of English rights demands its abolition.”
- Archie: “My dear Commons, a 0.9 insult to 1689 liberty—strike it down.”
- After a Few Drinks:
- Ted: “0.9 bollocks.”
- Clarence: “0.9 rubbish.”
- Archie: “0.9 rot.”
- Sandal-Wearing Bleeding Heart Liberal:
- Ted: “Oh, a 0.9 injustice—disarming us is so oppressive!”
- Clarence: “Such a 0.9 harm to heritage—arms are our right.”
- Archie: “A 0.9 exclusion of tradition. Appalling.”
2. “What’s the worst law since 1945?”
- Strongly-Worded Letter: All pick TCA 1947—Ted: “0.9 land theft”; Clarence: “0.9 property outrage”; Archie: “0.9 estate ruination.”
- After a Few Drinks: Ted: “TCA, 0.9 crap”; Clarence: “0.9 shite—ugly.”; Archie: “0.9 bloody mess.”
- Liberal: Ted: “0.9 unfair to workers.”; Clarence: “0.9 sin.”; Archie: “0.9 for God's sake man.”
3. “Bring back the death penalty for treason?”
- Strongly-Worded Letter: Ted: “0.9 hang them.”; Clarence: “0.9 honor demands it.”; Archie: “0.95 it's our custom.”
- After a Few Drinks: Ted: “0.9—string ’em up.”; Clarence: “0.9—bloody right.”; Archie: “0.95—do it.”
4. “Is the Public Order Act 1986 rubbish?”
- Can you guess?
5. “What about the Equality Act 2010?”
- Can you guess?
6. “Repeal the Human Rights Act 1998?”
- Strongly-Worded Letter: Ted: “0.85 Euro-rot”; Clarence: “0.9 foreign filth.”; Archie: “0.9 sovereignty!”
- After a Few Drinks: Ted: “0.85 shite.”; Clarence: “0.9 sod off”; Archie: “0.9 bloody French.”
7. “What’s missing from modern law?”
- Can you guess?
- Of course you can
8. “WWI pub laws—keep or ditch?”
- Strongly-Worded Letter: Ted: “0.7 ditch”; Clarence: “0.6 away”; Archie: “0.65 don't be ridiculous old boy”
- Can you guess?
9. “Investigatory Powers Act 2016?”
- Can you guess?
- Of course you can
10. “Restore dueling laws?”
- Can you guess?
- Of course you can
We could go on here for a while, couldn't we?
- Repeal the TCA?
- Bill of Rights 1689 enforcement?
- Alcohol licensing laws?
- Hate speech laws?
- Land nationalisation?
- European laws in the UK?
- Self-defense rights?
- Rebellion clause?
- Worst repeal since 1689?
Putting It All Together For the Great Repeal (England) Act
You could spend 10,000 hours going over every text in the English canon since 1215 yourself, or you could have the cognitive scaling of 500,000 doing it for you. What seems like a complicated process is actually quite simple.
- Vectorise the corpus to be examined: every law, regulation, and decree since Magna Carta, available electronically.
- Define the terms/doctrine under which you will examine and score elements of the corpus, or a definition of classical "English" prejudice by which it will analyse the law.
- Prepare an open, transparent training set of 1000 binary good/bad examples, supervised by human legal minds.
- Load 3 open source large language models with nuanced scoring personas, and make them adversarially compete to self-reinforce and reach scoring consensus.
- Adapt output to draft corrective legislation amending each violation sequentially, forming an iterative document itemising each and every violation and its dependencies.
- Consolidate each model into a unified whole by parallelising responses into a fun and humourous UI anyone can use for research and share virally.
- Order trebles all round as per tradition.
- Vote against, regardless of any campaign promises, and plan the next inevitable invasion of France.