Our Oppenheimer Moment: When Machines Learned Human Language


You've probably never heard of Jakob Uszkoreit and Menlo Park. You know Sam Altman (OpenAI) and maybe Geoffrey Hinton (the world's foremost AI scientist), but this German researcher gave up his PhD to found a group of 8 people at Google who made a discovery so profound it will now define the 21st century. In 2014, the same year the company bought British startup DeepMind, he created a way for machines and humans to communicate.
Why do you care? Because the AI black market for weapons, drugs, and fraud is here:
- https://www.scientificamerican.com/article/jailbroken-ai-chatbots-can-jailbreak-other-chatbots/
- https://www.thedailybeast.com/inside-the-underground-world-of-black-market-ai-chatbots
Words and speech are language, but so are numbers. And sign language. And musical notation. And dance. And the periodic table. Humans use language for expression of all kinds. The Industrial Revolution allowed humans to use machines to do work. What this group have done is allow humans to talk to those machines now - in numbers, and letters. It's a discovery en par with splitting the atom.
Google wanted to compete with Siri, and auto-complete search queries. Until then, AI had been an esoteric hobby of computer scientists. Uszkoreit devised an extremely clever way of processing massive amounts of text and understanding its context/meaning.

The people in this working group were (in paper order): Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Lukasz Kaiser, Illia Polosukhin. Google lost all of them, and lost the race to OpenAI.
A Less Boring History Of AI

If you've ever read up on AI, you'll know it's staggeringly dull. It's dense, tedious, over-academic, and frankly, boring. However, there are key moments to be aware of in the wider field of computer science which history will record:
- 1969: the US Defense Advanced Research Projects Agency (DARPA) created ARPANET, a way for computers to talk to one another;
- 1969: Ken Thompson led a working group to create AT&T Unix at Bell Labs, providing an operating system for the first mainframe computers;
- 1972: Butler Lampson outlined the first successful graphical personal computer (Xerox Alto) at Xerox PARC (Palo Alto Research Center);
- 1989: Tim Berners-Lee created Hypertext Transfer Protocol (HTTP) at CERN, which allowed people to publish and navigate content on those computers;
- 1991: Phil Zimmermann published source code for encryption as Pretty Good Privacy (PGP), allowing computers to communicate securely outside of the military for the first time;
- 1996: at Stanford University, Larry Page and Sergey Brin solved the Eigenvalue problem with PageRank, which helped sort academic literature;
- 2008: anonymous author Satoshi Nakamoto created the Blockchain, a way for computers to work decentralised without trusting one another;
- 2014: at Google, Jakob Uszkoreit created the Self-Attention mechanism and Transformer architecture, allowing machines to learn human language.
You'll notice none of these mention the people you know - Bill Gates, Steve Jobs, Jeff Bezos, Mark Zuckerberg etc - because they didn't invent or discover anything. They simply commercialised it. Which is also true of Sam Altman, of OpenAI.
The key thing to know about AI is - up until 2014 - it wasn't really going anywhere. The entire field was orientated towards Neural Networks as the answer to everything, but they wouldn't scale up properly.
Most of this has been led by IBM. Ex-Google employees took their ideas to OpenAI, which led to GPT.
- 1997: IBM's Deep Blue defeats world chess champion Garry Kasparov, marking a milestone in AI's ability to compete with humans in complex strategic games.
- 1998: Introduction of Long Short-Term Memory (LSTM) networks by Sepp Hochreiter and Jürgen Schmidhuber, which become a key component in many future AI applications, particularly in natural language processing.
- 2006: Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh publish a paper on Deep Belief Networks, which helps revive interest in deep learning and neural networks.
- 2009: ImageNet, a large-scale image database, is introduced, enabling significant advancements in computer vision and deep learning.
- 2011: IBM's Watson defeats human champions in the quiz show Jeopardy!, showcasing the potential of AI in natural language processing and information retrieval.
- 2012: AlexNet, a deep convolutional neural network architecture, achieves breakthrough performance in the ImageNet Large Scale Visual Recognition Challenge, revolutionizing the field of computer vision.
- 2014: Generative Adversarial Networks (GANs) are introduced by Ian Goodfellow et al., enabling the generation of realistic images and other data types.
- 2015: Google DeepMind's AlphaGo defeats world champion Lee Sedol in the complex game of Go, demonstrating the power of deep reinforcement learning.
- 2017: Transformer architecture is introduced in the paper "Attention Is All You Need" by Vaswani et al., becoming the foundation for state-of-the-art language models like BERT and GPT.
- 2020: OpenAI releases GPT-3 (Generative Pre-trained Transformer 3), a massive language model with 175 billion parameters, showcasing impressive language generation capabilities.
Staggeringly boring. All discoveries are, really.
Nobody cared. They even named it in such a boring way, it's impossible to believe you could have a simple conversation with these types of people.
But there was some fun in there at least:
Together, the three researchers drew up a design document called “Transformers: Iterative Self-Attention and Processing for Various Tasks.” They picked the name “transformers” from “day zero,” Uszkoreit says. The idea was that this mechanism would transform the information it took in, allowing the system to extract as much understanding as a human might—or at least give the illusion of that. Plus Uszkoreit had fond childhood memories of playing with the Hasbro action figures. “I had two little Transformer toys as a very young kid,” he says. The document ended with a cartoony image of six Transformers in mountainous terrain, zapping lasers at one another.
https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/
Understanding The Terminology: ELI5
AI is full of obscure academic jargon. It helps to understand it more simply. "Explain Like I'm Five" (ELI5) is useful.
In this patronising analogy, imagine you have a toy car that you want to play with, but you don't have the actual car.

Model
Instead of having the car, you have a small replica of the car that looks and works just like the real one, but it's much smaller. This small replica is called a "model" of the car.
In a similar way, when we talk about language models, we're talking about a kind of "toy" version of how language works in the real world. Just like the toy car, a language model is a smaller, simpler representation of something much bigger and more complex.
Transformer
A "transformer" - just like film and real-life toys - is like a special kind of toy vehicle that can change into different shapes, like a robot. This special toy helps the other toy vehicles work together more efficiently.
Vectors
Imagine each toy vehicle has a unique set of features, like its color, size, and shape. We can describe these features using numbers, like saying the toy car is small (1), red (2), and has four wheels (4). These numbers represent a "vector," which is a way to describe something about the car.
Tokens
Just like you can break down a toy car into smaller parts, like the wheels, doors, and engine, you can break down a sentence into smaller pieces called "tokens." These tokens can be words or even parts of words.
Training
When you play with your toy vehicles, you might teach them new tricks or ways to work together. This is similar to "training" a language model. During training, the model learns from many examples of text, just like you teach your toys by playing with them and showing them what to do.
Parameters
Let's say you want to make your toy vehicles behave in a specific way. You might adjust their settings, like how fast they can go or how they respond to obstacles. These settings are like "parameters" in a language model. Parameters are values that control how the model behaves and learns.
Neural Network
Imagine that instead of just one toy car, you have a whole collection of toy cars, trucks, and other vehicles. These toys are connected to each other in a way that allows them to work together, just like a team.
Self-Attention (the discovery)
Picture each toy vehicle paying attention to what the other vehicles are doing. For example, the toy ambulance might watch the toy police car to see if it needs to follow it to an emergency. This is similar to "self-attention" in a language model, where different parts of the model pay attention to each other to understand how they're related.
Inference
Imagine that you have a toy city with various toy vehicles, representing a trained language model. The toy vehicles have learned to navigate the city, follow traffic rules, and perform specific tasks based on their training. You want to use this toy city to simulate a real-world scenario. You introduce a new toy vehicle, representing a new input or prompt, into the city. This new vehicle could be a toy ambulance that needs to reach a specific destination quickly. The trained toy vehicles in the city will use their learned knowledge and behaviors to interact with the new ambulance. They may clear the way for the ambulance, guide it through the optimal route, and help it reach its destination efficiently. You are observing how the toy city and its vehicles respond to this new vehicle.
Large Language Model (LLM)
Imagine you have a massive toy city with thousands of toy vehicles, including cars, trucks, buses, and more. This toy city represents a Large Language Model (LLM).
Each toy vehicle in the city has a specific role and is connected to many other vehicles, forming a complex network. These connections allow the vehicles to work together and share information, just like the different parts of an LLM.
The toy vehicles are constantly communicating with each other, paying attention to what the others are doing. For example, when a toy ambulance rushes to an emergency, the toy traffic lights and other vehicles respond accordingly. This is similar to how the parts of an LLM use self-attention to understand the relationships between words and sentences.
Some of the toy vehicles, like the transformers, have special abilities that help the entire city work more efficiently. They can change shape and adapt to different situations, just like how transformers in an LLM help the model understand and generate language more effectively.
Each toy vehicle has unique features that can be described using numbers, like its size, color, and purpose. These numbers form a "vector" that represents the vehicle. Similarly, in an LLM, words and phrases are represented by vectors that capture their meaning and properties.
The toy city is divided into smaller sections, like neighborhoods and streets. These sections are like the "tokens" in an LLM, which are the smaller parts that make up the overall structure of the language.
To make the toy city function properly, you need to teach the vehicles how to work together. This is like "training" an LLM, where the model learns from vast amounts of text data to understand patterns and relationships in language.
You can fine-tune the toy city by adjusting various settings, such as the speed limits, traffic light timings, and vehicle routes. These settings are similar to the "parameters" in an LLM, which control how the model learns and generates language. By tweaking these parameters, you can adapt the LLM to perform better on specific tasks.
What Was The Discovery?
Well, read it for yourself. If you can get through it.
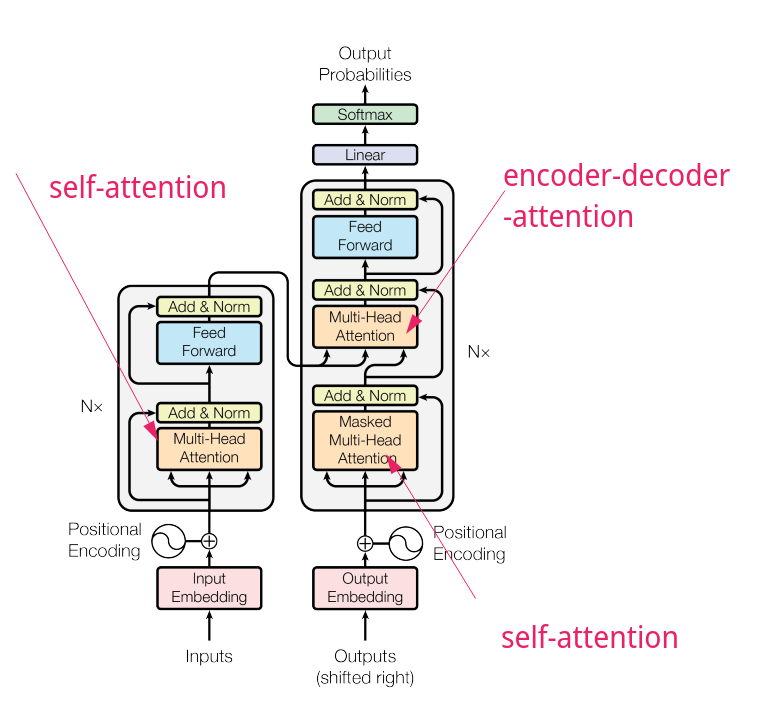
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
https://arxiv.org/abs/1706.03762
Huh?
Wired puts it aptly:
Soon after the paper was published, OpenAI’s chief researcher, Ilya Sutskever—who had known the transformer team during his time at Google—suggested that one of its scientists, Alec Radford, work on the idea.
The results were the first GPT products. As OpenAI CEO Sam Altman told me last year, “When the transformer paper came out, I don’t think anyone at Google realized what it meant.”
We still don't, Sam. Nobody does. It's academic gibberish.
Let's break it down.
Self-attention is a mechanism that allows a computer brain (a language model) to weigh the importance of each word in the sentence when processing and understanding the meaning of the sentence as a whole. It helps the model capture the relationships and dependencies between words.
Imagine you're reading a book, and you want to understand the meaning of a specific word. To do that, you consider the context around the word, looking at the other words in the same sentence or paragraph.
Self-attention in a Transformer works similarly. It allows the AI model to look at all the words in a sentence and determine which words are most important for understanding each specific word. By considering the context and relationships between words, self-attention helps the model comprehend the overall meaning of the sentence. It's a bit like PageRank and how it determines which links/sources should be considered the most important.
Transformers are like super-powered reading assistants that use self-attention to process and understand text, enabling them to perform tasks like answering questions, writing stories, or translating languages with remarkable accuracy and fluency.
Here's how self-attention works step by step:
- Word Embeddings:
- Each word in the sentence is converted into a dense vector representation called a word embedding.
- In our example, each word ("The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog") would have its own word embedding.
2. Query, Key, and Value Vectors:
- For each word, three vectors are computed: a query vector (Q), a key vector (K), and a value vector (V).
- These vectors are obtained by multiplying the word embeddings with learned weight matrices.
- The query, key, and value vectors are used to compute the attention scores and values.
3. Attention Scores:
- For each word, the model computes attention scores with respect to all other words in the sentence.
- The attention score between two words indicates how much importance the model should give to one word when processing the other.
- The attention scores are computed by taking the dot product of the query vector of one word with the key vectors of all other words.
4. Softmax and Attention Weights:
- The attention scores are passed through a softmax function to normalize them into attention weights.
- The softmax function converts the scores into probabilities that sum up to 1.
- The attention weights determine how much each word should contribute to the representation of the current word.
5, Weighted Sum of Values:
- The attention weights are then multiplied with the corresponding value vectors of all words.
- The resulting weighted sum represents the self-attended representation of the current word.
- This step allows the model to gather relevant information from other words based on their attention weights.
6. Repeating the Process:
- Steps 3-5 are repeated for each word in the sentence.
- This means that each word attends to all other words and computes its self-attended representation.
7. Combining Self-Attended Representations:
- The self-attended representations of all words are combined to obtain the final representation of the sentence.
- This final representation captures the important relationships and dependencies between words in the sentence.
In the classic example sentence "The quick brown fox jumps over the lazy dog":
- The word "jumps" would attend more to "fox" and "over" because they are related to the action.
- The word "lazy" would attend more to "dog" because it is describing the dog.
- The word "brown" would attend more to "fox" because it is describing the fox.
By weighing the importance of each word based on its relationships with other words, self-attention helps the model understand the overall meaning and context of the sentence.
The final representation is a condensed summary of the sentence that encodes its meaning and context, and contains information about the key elements and their relationships, such as:
- The main subject of the sentence: "fox"
- The action performed by the subject: "jumps"
- The adjectives describing the subject: "quick" and "brown"
- The object of the action: "dog"
- The adjective describing the object: "lazy"
- The preposition linking the action and the object: "over"
The final representation is a high-dimensional vector, typically with hundreds or thousands of dimensions. Each dimension in the vector captures a specific aspect or feature of the sentence, such as the presence of certain words, their relationships, or the overall semantic meaning.
Let's say the final representation is a 500-dimensional vector:
- Dimension 1: Represents the presence and importance of the word "fox"
- Dimension 2: Represents the presence and importance of the word "jumps"
- Dimension 3: Represents the relationship between "fox" and "jumps"
- Dimension 4: Represents the presence and importance of the word "dog"
- Dimension 5: Represents the relationship between "jumps" and "over"
- etc etc
- Dimension 500: Represents the overall semantic meaning of the sentence.
The high dimensionality of the representation is one of the reasons why Transformers have been successful in achieving state-of-the-art performance on various natural language processing tasks. They can capture and leverage a vast amount of information from the input text to make accurate predictions and generate coherent and contextually relevant responses.
And If You're A Developer?
What's so bizarre about all of this is how weirdly simple this stuff is. LLMs are PyTorch or TensorFlow projects which take in CSV files, and spit out binary files (.bin) as their super-cool-amazing AI. That's it.
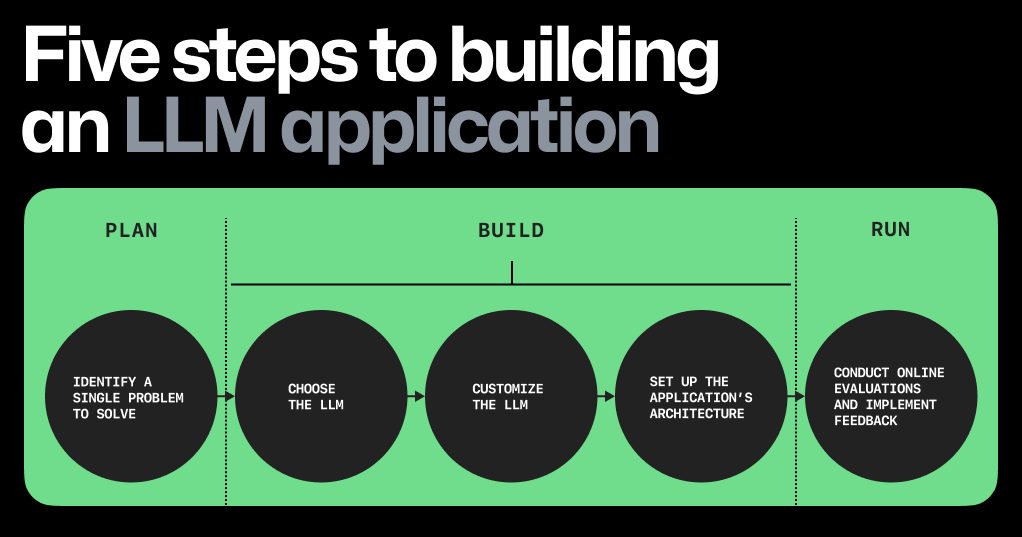
If your model is a 100GB .bin file, you're going to have trouble running that Python script each time. More on that in a second.
LLM library structure
When you download and unzip a typical Large Language Model (LLM) from Hugging Face (HF), you'll usually find a directory structure that looks something like this:
model_name/
├── config.json
├── merges.txt (or vocab.json)
├── pytorch_model.bin (or tf_model.h5)
├── special_tokens_map.json
├── tokenizer_config.json
└── tokenizer.jsonLet's break down each component:
config.json:
- This file contains the configuration parameters of the LLM.
- It includes information such as the model architecture, number of layers, hidden size, attention heads, and other hyperparameters.
- The configuration file is used to initialize the model and ensure it is set up correctly.
merges.txt (or vocab.json):
- This file contains the vocabulary of the LLM.
- In the case of
merges.txt, it includes the subword merges used by the tokenizer to split words into subword units. - If the model uses a different tokenization method, like WordPiece or SentencePiece, the vocabulary may be stored in a file named
vocab.jsoninstead.
pytorch_model.bin (or tf_model.h5):
- This is the main file that contains the pre-trained weights of the LLM.
- If the model is a PyTorch model, the file will be named
pytorch_model.bin. - For TensorFlow models, the file may be named
tf_model.h5or have a different extension. - This file is usually the largest in size, as it holds all the learned parameters of the model.
special_tokens_map.json:
- This file contains a mapping of special tokens used by the model, such as
[PAD],[UNK],[CLS],[SEP], etc. - Special tokens are used to represent specific functions or markers in the input and output sequences.
- The mapping helps the tokenizer correctly handle and identify these special tokens.
tokenizer_config.json:
- This file contains the configuration parameters for the tokenizer.
- It includes information such as the tokenizer type (e.g., BPE, WordPiece, SentencePiece), special token mappings, and other tokenizer-specific settings.
tokenizer.json:
- This file contains the actual tokenizer object used to tokenize the input text.
- It includes the necessary data and methods to perform tokenization, such as splitting text into tokens, converting tokens to IDs, and handling special tokens.
These files work together to define and instantiate the LLM. The configuration files provide the necessary settings, the vocabulary files contain the subword units or tokens, the model file holds the pre-trained weights, and the tokenizer files handle the tokenization process.
Example REST-JSON-to-model call
Import the library, send it text from a POST, respond 200 with its reply. It's trivial.
from transformers import AutoTokenizer, AutoModelForCausalLM
from flask import Flask, request, jsonify
app = Flask(__name__)
# Load the pre-trained LLM and tokenizer
model_name = "gpt-3.5-turbo"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
@app.route("/generate", methods=["POST"])
def generate_text():
prompt = request.json["prompt"]
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return jsonify({"generated_text": generated_text})
if __name__ == "__main__":
app.run()How Do You Load A 100GB Binary File Each Time?
Good question. You don't. You can't load that file every time from disk, which means RAM (like Redis, for example). Most machines just don't have more than 32GB of RAM individually. Which poses a problem.
The answer? Graphics cards.

Lots and lots and LOTS of graphics cards chained together. You're basically building a supercomputer gaming PC. To tackle this problem, we need to employ some strategies:
Splitting the Data:
- Just like you would split a large dataset into smaller chunks or partitions, we need to divide the language model into smaller parts.
- Each part contains a portion of the model's data and can be loaded into memory separately.
- This is similar to breaking down a large JSON file into smaller JSON files or database tables.
Distributed Processing:
- To handle the large language model, we need to distribute the workload across multiple machines or servers.
- Each machine takes responsibility for processing a specific part of the model.
- The machines communicate and coordinate with each other to share intermediate results and generate the final output.
- This is similar to having multiple servers in a web application, each handling a specific task or serving a portion of the data.
Lazy Loading and Caching:
- Instead of loading the entire language model into memory at once, we can implement lazy loading and caching techniques.
- We load only the necessary parts of the model into memory when needed, similar to how you would lazy load resources in a web application.
- Frequently accessed or computed parts of the model can be cached to improve performance and reduce memory usage.
- This is analogous to caching frequently accessed data or rendered pages in a web application.
Efficient Data Representation:
- To optimize memory usage and processing speed, we can use efficient data representations for the language model.
- This involves techniques like compression, quantization, or using lightweight data formats.
- It's similar to optimizing the size and format of your web application's assets, such as compressing images or minifying JavaScript and CSS files.
Asynchronous Processing:
- Loading and processing a large language model can be time-consuming, so we need to handle it asynchronously to prevent blocking the main application.
- We can use techniques like background processing, worker threads, or message queues to handle the model-related tasks in the background.
- This is similar to using asynchronous JavaScript or background jobs in a web application to handle long-running tasks without freezing the user interface.
By applying these strategies, we can effectively load and utilize a large language model like a 2TB model in a distributed and efficient manner. It involves breaking down the model into manageable parts, distributing the workload across multiple machines, lazy loading and caching data, using efficient data representations, and employing asynchronous processing techniques.
When it comes to physically setting up the hardware for running a large language model like a 2TB model, it involves assembling a system with multiple GPUs (Graphics Processing Units) to distribute the workload and memory requirements.
- Start with a case. A big one. Lian Li PC-O11 Dynamic, Fractal Design Define 7, or Corsair Obsidian Series.
- If you're using 4 GPUs, you'll need a motherboard with at least 4 PCIe x16 slots, such as the ASUS ROG Zenith II Extreme, Gigabyte AORUS XTREME, or MSI MEG series motherboards.
- GPUs eat electricity. You need a high-wattage modular power supply unit (PSU) that can handle the power requirements of multiple GPUs and other components. Examples are the Corsair AX series, EVGA SuperNOVA series, or Seasonic Prime series.
- GPUs get hot. Really hot. You need high-performance aftermarket CPU coolers with large heatsinks and fans. Something like the Noctua NH-D15 CPU, Corsair Hydro Series liquid coolers, or EK-Quantum custom liquid cooling.
- Popular choices for GPU-accelerated machine learning include NVIDIA GPUs like the Tesla, GeForce, or Quadro series.
GPT-3 is one of the largest language models to date, with 175 billion parameters. OpenAI used a cluster of 1,024 V100 Tensor Core GPUs for training the model, each with the power of 32 CPUs, 32GB RAM, and a power consumption of around 300-350 watts: https://www.nvidia.com/en-us/data-center/v100/ .
Comparing the sizes:
- GPT-3 was the largest model in the GPT family a year ago, with 175 billion parameters. Each parameter in the model is typically represented as a 32-bit floating-point number, which requires 4 bytes of storage. 175 billion * 4 bytes ≈ 700 GB.
- GPT-2 is a smaller model compared to GPT-3, but it still has a substantial size. With 1.5 billion parameters, the storage requirement is approximately 1.5 billion * 4 bytes ≈ 6 GB.
- GPT-Neo is an open-source model with a size comparable to GPT-2. With 2.7 billion parameters, the storage requirement is approximately 2.7 billion * 4 bytes ≈ 11 GB.
- GPT-J is a larger open-source model compared to GPT-2 and GPT-Neo. With 6 billion parameters, the storage requirement is approximately 6 billion * 4 bytes ≈ 24 GB.
Let's cost that up with 4 GPUs:
- Corsair Obsidian = $500.
- ROG Zenith II Extreme = $1500.
- Corsair AX = $600.
- A V100 is ~$1500 = (4 x $1500) = $6000.
Total cost for a 4 GPU / 128GB RAM system = $8600.
Falcon 180B is a super-powerful language model with 180 billion parameters, trained on 3.5 trillion tokens. It's currently at the top of the Hugging Face Leaderboard for pre-trained Open Large Language Models and is available for both research and commercial use: https://huggingface.co/tiiuae/falcon-180B
Type | Kind | Memory | Example | |
|---|---|---|---|---|
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
The maintainers of this PyTorch project beast say:
Falcon 180B was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute.
since the 180B is larger than what can easily be handled with transformers+acccelerate, we recommend using Text Generation Inference.
You will need at least 400GB of memory to swiftly run inference with Falcon-180B.
https://huggingface.co/blog/falcon-180b
Scaling up from earlier, you'd need:
- Corsair Obsidian = (4 X $500) = $2000.
- ROG Zenith II Extreme = (4 X $1500) = $6000.
- Corsair AX = (4 X $600) = $3600.
- A V100 is ~$1500 = (12 x $1500) = $18000.
Total cost for a 12 GPU / 384GB RAM system = $29,600.
How Can I Get Started?
It's the question everyone has.
- Read: https://www.amazon.com/You-Look-Like-Thing-Love/dp/0316525227
- Read: https://www.amazon.com/Master-Algorithm-Ultimate-Learning-Machine/dp/0465094279
- Amazon Bedrock allows you to host your own LLM without the BS: https://aws.amazon.com/bedrock/
- Learn Python using ChatGPT or Claude: https://www.learnpython.org/
- Learn Google TensorFlow using ChatGPT or Claude: https://www.tensorflow.org/
- Learn Facebook PyTorch using ChatGPT or Claude: https://pytorch.org/
- Learn VectorDB using ChatGPT or Claude: https://vectordb.com/
- Get a HuggingFace account to download and experiment with models: https://huggingface.co/