A Searchable Multi-Language Bible In Less Than An Hour With Elasticsearch + Go


As the original corpus, the bible is 66 books containing 31,102 verses, for a total of 783,131 words. Storing that in a database is trivial. Anyone can do it, for free, in less than an hour. If you're a techie, read on.
For the impatient, go to: https://github.com/devilslane-com/bible-golang-elasticsearch
First, A Data Source
Finding bible verses is easy. Chapter summaries, for some reason, are far more difficult. There are many of the former:
- https://github.com/scrollmapper/bible_databases
- https://github.com/godlytalias/Bible-Database
- https://github.com/thiagobodruk/bible
We'll use the last one. Download the Bible in basic English as a static file from: https://github.com/thiagobodruk/bible/blob/master/json/en_bbe.json
The format is simple:
[
{
"abbrev" : "abbrev"
"book" : "name"
"chapters":
[
["Verse 1", "Verse 2", "Verse 3", "..."],
["Verse 1", "Verse 2", "Verse 3", "..."],
["Verse 1", "Verse 2", "Verse 3", "..."]
]
}
]Set Up Elasticsearch
You should have Docker installed as a prerequisite; Docker Desktop (https://www.docker.com/products/docker-desktop/) if on Windows or Mac.
Download the latest image of Elasticsearch so you can use it, from: https://hub.docker.com/_/elasticsearch
# Syntax: docker pull elasticsearch/<version>
docker pull elasticsearch/8.12.0Start a container
Run from the terminal:
docker network create elastic
docker run --name elasticsearch --net elastic -p 9200:9200 -it -m 4GB -d elasticsearch:8.12.0What this does:
- Creates a separate network;
- Creates a new container on that network called "elasticsearch" (this can be anything you like);
- Binds Elasticsearch's HTTP server to port 9200 on the container and your machine;
- Instructs the server to interactively (`-it`) print the HTTP password out (-p) for the user "elastic";
- Sets the internal JVM heap size to 4GB (ideally, 25-50% of your machine's RAM);
- Daemonize and run in the background (`-d`).
Now visit some URLs:
- https://localhost:9200/
- https://localhost:9200/_cat/nodes?v&pretty
- https://localhost:9200/_cat/indices?v&pretty
Install Elasticvue to view data
Elasticsearch is a headless REST API which stores searchable records as JSON documents rather than "rows" like a standard database. It has no GUI program. You typically talk to it through a programming language.
There are a few attempts at a UI for Elasticsearch, but they're crap. The one you want is called Elasticvue: https://elasticvue.com/ .
Download, install, and create a new cluster with HTTP basic auth. Test and save your connection.
Important Info
- Elasticsearch is extremely hungry for RAM and CPU. As a Java program, you need to set its JVM heap size (i.e. how much RAM it is allowed), and it will consume it with abandon.
- It is sensitive to overloading and crashing. Go gently.
- The host is HTTPS by default now. It is https://localhost:9200, not http:// as before. You will get a self-signed certificate warning in your browser.
- The SSL runs on port 9200, not 443.
- Security is on by default. You must supply HTTP basic auth to connect. The default username is elastic.
- To get the HTTP basic auth password, you must consult the Docker container's logs. You will see an entry on startup like so:
2024-02-06 12:40:49 ℹ️ Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
2024-02-06 12:40:49 F3ZlDEscFV8VTisZ7yzfA Bit Of Theory: Define The Elasticsearch Index
We need to tell Elasticsearch how to store the data, and how we'll be sending it. But first, it's important to understand how it works. It's crucial to understand the Bible is available in 100+ languages, including Arabic, Russian, Japanese etc.
What we want is each document (row) to be something like this:
{
"abbrev": "gn",
"chapter": 1,
"verse": 3,
"en": "And God said, Let there be light: and there was light.",
"fr": "Et Dieu dit: Que la lumière soit! Et la lumière fut.",
"es": "Y dijo Dios: Sea la luz; y fue la luz."
}Chapter and verse are INT, and the rest are STRING.
Demystifying the academic terminology
Elasticsearch is built on top of Apache Lucene (https://lucene.apache.org/), a high-performance, full-featured text search engine library. When a document is indexed in Elasticsearch, it goes through an analysis process where the specified analyzer tokenizes the text and applies various filters, including stemming. This processed text is then indexed. During a search query, the same analysis process is applied to the query text, and the search is performed on the processed tokens.
Tokenization is the process of breaking down text into smaller pieces. A document is broken down into smaller words or terms which are then indexed. For example, the sentence "Left wing people are childish morons" would be tokenized into "left", "wing", "people", "are", "childish" and "morons".
So tokens are the result of splitting up text into smaller pieces.
N-grams are a method used in text processing where a given sequence of text is broken down into n-grams (substrings) of a specified length. For example, the word "gold" can be broken down into 2-grams like "go", "ol", "ld". Think... autocomplete.
So, n-grams are when we break it down further, and break the words apart into pieces which can make different combinations.
Stemmers are used to reduce words to their root form. For instance, the root of "running", "runs", and "ran" is the verb to "run". This enables users to search for a term in any variation and still find relevant results.
Creating the index
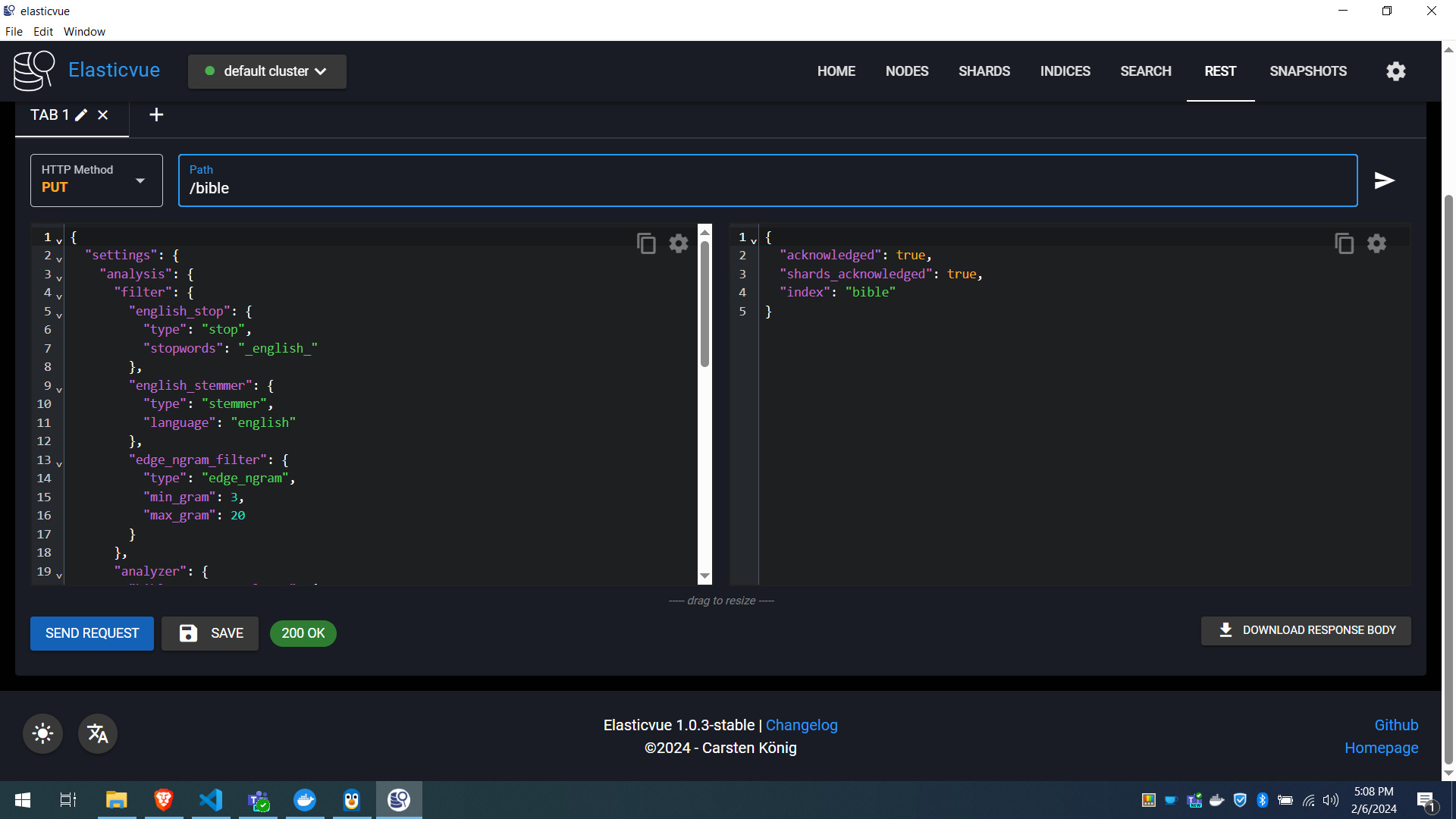
To add the index definition or schema, we simply send a PUT request with a JSON body which specifies the fields we want (the columns or "mappings"), and the settings of how to digest it.
{
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stemmer": {
"type": "stemmer",
"language": "english"
},
"french_stop": {
"type": "stop",
"stopwords": "_french_"
},
"french_stemmer": {
"type": "stemmer",
"language": "french"
},
"spanish_stop": {
"type": "stop",
"stopwords": "_spanish_"
},
"spanish_stemmer": {
"type": "stemmer",
"language": "spanish"
},
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 3,
"max_gram": 20
}
},
"analyzer": {
"bible_custom_analyzer_english": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"edge_ngram_filter",
"english_stop",
"english_stemmer"
]
},
"bible_custom_analyzer_french": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"edge_ngram_filter",
"french_stop",
"french_stemmer"
]
},
"bible_custom_analyzer_spanish": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"edge_ngram_filter",
"spanish_stop",
"spanish_stemmer"
]
}
}
}
},
"mappings": {
"properties": {
"book": {
"type": "keyword"
},
"chapter": {
"type": "integer"
},
"verse": {
"type": "integer"
},
"en": {
"type": "text",
"analyzer": "bible_custom_analyzer_english"
},
"fr": {
"type": "text",
"analyzer": "bible_custom_analyzer_french"
},
"es": {
"type": "text",
"analyzer": "bible_custom_analyzer_spanish"
}
}
}
}This looks long but it's easy, and repetitive.
The bottom piece is simple: set up 6 fields/columns. Book is a slug or keyword; chapter and verse are integers. The content of the verse text is stored against its language as searchable text. Each language is assigned a different analyzer.
Explanation of the analyzer
Elasticsearch will tokenize the sentence "And God said, Let there be light: and there was light" like this:
- And
- God
- said
- Let
- there
- be
- light
- and
- there
- was
- light
We define a set of filters to narrow it down a bit. Elasticsearch has over 50 of them.
First, stop words to ignore. STOP words are common things we don't care about: and, or, the, if, was, will etc.
- English STOP words;
- French STOP words;
- Spanish STOP words;
More: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-tokenfilter.html
Next, stemmers to apply to verbs we find, so we can generate variations. If someone searches for "jumping", we know to include "jump" as that's where it's from.
- English verb stems;
- French verb stems;
- Spanish verb stems;
More: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stemmer-tokenfilter.html
Lastly, n-grams. we instruct the Lucene engine to break all words and tokens into tiny pieces (substrings). This slices up letter combinations with a minimum of 3 characters from each word, up to 20 characters.
Applying the edge n-gram filter with min_gram=3 and max_gram=20 to each term would result in tokens such as:
- And: And
- God: God
- said: Sai, Said
- Let: Let
- there: The, Ther, There
- be: (No token generated, as "be" is shorter than the
min_gramof 3) - light: Lig, Ligh, Light
- and: And
- there: The, Ther, There
- was: Was
- light: Lig, Ligh, Light
For each term, the edge n-gram filter generates tokens (word pieces) starting from the first character and increases in length until it either reaches the term's full length or the max_gram limit. In this scenario, because the min_gram is set to 3, any term shorter than 3 characters (like "be") does not produce any tokens. Terms that are exactly 3 characters long (like "And", "God", "Let") generate a single token, which is the term itself. Longer terms generate multiple tokens, starting from the minimum length of 3 characters up to the term's full length or the max_gram limit, whichever is smaller.
This approach with a min_gram of 3 reduces the number of very short, often less meaningful tokens, which can help focus the search and matching process on more significant parts of terms. It's particularly useful for supporting autocomplete and partial match features where at least a few initial characters of the search term are known.
If we used a minimum length of 2, we'd get:
Applying the edge n-gram filter with min_gram=2 and max_gram=20 to each term would result in tokens like:
- And: An, And
- God: Go, God
- said: Sa, Sai, Said
- Let: Le, Let
- there: Th, The, Ther, There
- be: Be
- light: Li, Lig, Ligh, Light
- and: An, And
- there: Th, The, Ther, There
- was: Wa, Was
- light: Li, Lig, Ligh, Light
More matches, more mess and ambiguity.
Finally, we instruct Elasticsearch to tokenize the verse text, and then apply a chain of these filters. Together, these form an analyzer.
For each language, we run a simple chain:
"bible_custom_analyzer_english": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"edge_ngram_filter",
"english_stop",
"english_stemmer"
]
},What this means is:
- Break the words into smaller pieces (tokens);
- Convert everything to lowercase to make it case-insensitive;
- Break the tokens up into n-grams of 3 characters or more;
- Remove the language's stop words;
- Apply the language's verb stemming.
Available token filters
Building an accurate search is a labour of love and overwhelming at first. Much can be done with Elasticsearch's configurability.
ascii_folding: Converts characters from the ASCII set to their closest ASCII equivalents, useful for handling accents and special characters in text.edge_ngram: Generates tokens from the beginning edge of a word up to a specified length, aiding in autocomplete and partial match searches.ngram: Creates substrings of a given token within specified length ranges, useful for detailed text analysis and partial matching.apostrophe: Removes apostrophes and characters following them, simplifying text by eliminating possessive forms of nouns.arabic_normalization: Normalizes Arabic characters to enhance text matching by reducing variations in the written form.bengali_normalization: Normalizes Bengali characters, addressing common spelling and typing variations.brazilian_stem: Applies stemming for Brazilian Portuguese, reducing words to their base or root form to improve matching.cjk_bigram: Forms bigrams of CJK (Chinese, Japanese, Korean) terms to improve text analysis and search for these languages.cjk_width: Normalizes full-width and half-width characters to a single width in CJK texts, ensuring consistency.classic: Filters out classic English stopwords and tokens, cleaning up common words that might dilute search relevance.common_grams: Identifies and preserves common but important words that might be removed by other filters, such as stopwords.condition: Applies a specific filter based on a defined condition, offering conditional text processing.decimal_digit: Converts all digits to their decimal representation, ensuring numerical data is uniformly represented.delimited_payload: Extracts payloads (metadata) from tokens, allowing additional data to be associated with specific tokens.dictionary_decompounder: Breaks down compound words into their constituent parts, enhancing the analysis of languages that use compounding.elision: Removes elisions (contractions) from tokens, typically in languages like French, to simplify analysis.fingerprint: Creates a condensed version of the input by removing duplicates and sorting the tokens, useful for deduplication.flatten_graph: Ensures token streams that represent graphs are converted into a flat list of tokens, necessary for certain advanced text processing tasks.hindi_normalization: Normalizes Hindi characters to address common variations and improve text matching.hyphenation_decompounder: Splits compound words that are hyphenated into their individual components for languages where this is common.icu_collation: Uses ICU (International Components for Unicode) for advanced, locale-sensitive text sorting and filtering.icu_folding: Applies ICU-based folding to normalize text, extendingascii_foldingto a broader range of characters.icu_normalizer: Normalizes text using ICU, addressing a wide range of linguistic variations for global text compatibility.icu_tokenizer: Tokenizes text based on ICU, capable of handling a vast array of languages and scripts.icu_transform: Transforms text using an ICU transform, such as changing script or applying complex character mappings.indonesian_stem: Reduces Indonesian words to their base form, improving the search and analysis for this language.irish_lower: Specifically targets Irish lowercase conversions, considering language-specific rules for casing.keep: Keeps only tokens found in a specified list, filtering out all others to focus analysis on relevant terms.keep_types: Retains tokens of specific types (based on token type attributes), enabling targeted text processing.keyword_marker: Marks certain terms as keywords, preventing them from being modified by subsequent filters like stemming.kstem: Applies a light stemmer for English, offering a balance between aggressive stemming and maintaining word integrity.length: Filters tokens based on their character length, setting minimum and/or maximum size criteria.limit: Limits the number of tokens processed, useful for controlling analysis on very large texts.lowercase: Converts all tokens to lowercase, standardizing token case for more consistent analysis.min_hash: Generates a MinHash token set for approximate duplicate detection, useful in large datasets.multiplexer: Applies multiple filters in parallel to the same token stream, combining their outputs.norwegian_normalization: Normalizes Norwegian characters, addressing common variations for better matching.pattern_capture: Captures tokens based on a regex pattern, allowing for selective token extraction.pattern_replace: Replaces tokens matching a regex pattern with specified text, offering search-and-replace functionality.persian_normalization: Normalizes Persian text by addressing character variations, enhancing search accuracy.phonetic: Applies phonetic encoding to tokens, making it possible to match words based on their pronunciation.porter_stem: Utilizes the Porter stemming algorithm for English, reducing words to their root forms.predicate_token_filter: Filters tokens based on a script predicate, offering highly customizable token filtering.remove_duplicates: Eliminates duplicate tokens, cleaning up token streams for clearer analysis.reverse: Reverses each token, useful in certain analytical or search scenarios.russian_stem: Applies stemming for Russian, condensing words down to their base or stem form.scandinavian_folding: Normalizes Scandinavian characters by folding them into more basic forms, aiding in cross-language compatibility.scandinavian_normalization: Normalizes characters specific to Scandinavian languages, improving text matching.serbian_normalization: Addresses Serbian language character variations through normalization.shingle: Creates shingles (token groups) from token streams, useful for certain types of phrase matching or analysis.snowball: Applies the Snowball stemmer to tokens, offering language-specific stemming for multiple languages.sorani_normalization: Normalizes Sorani Kurdish characters, enhancing analysis and search for this language.stemmer: Reduces words to their stem forms based on language-specific rules, essential for consistent search results across word forms.stemmer_override: Overrides the default stemmer results with custom defined mappings, allowing for corrections or exceptions.stop: Removes stop words from token streams, filtering out common but typically less meaningful words.synonym: Matches tokens against a list of synonyms, expanding or replacing terms based on defined relationships.synonym_graph: Similar tosynonym, but produces a token graph to represent multi-word synonyms and homonyms accurately.trim: Trims leading and trailing whitespace from tokens, cleaning up token boundaries.truncate: Truncates tokens to a specified length, ensuring no token exceeds a maximum size.unique: Removes duplicate tokens from the stream, ensuring each token is unique.uppercase: Converts all tokens to uppercase, standardizing token case for certain analytical needs.word_delimiter: Splits tokens based on word boundaries, such as when letters and digits meet, enhancing tokenization.word_delimiter_graph: Similar toword_delimiter, but produces a token graph to accurately represent split tokens and potential combinations.
Each filter offers unique text processing capabilities, enabling Elasticsearch to be highly adaptable and effective for a wide range of text analysis and search scenarios across different languages and data types.
Import the JSON data
This is where we need some custom code, because the index is "flat" and the source data is contained in an array. The Bible contains 31,102 verses, so we should expect 31,102 documents (rows).
Only one problem: Elasticsearch will easily fall over with 50+ requests, so we need to use its BulkIndexer via the official Go client: https://github.com/elastic/go-elasticsearch .
The full code is here: https://github.com/devilslane-com/bible-golang-elasticsearch/blob/develop/src/elasticbible/import/main.go
This file has a BOM which causes trouble when importing the file, so we remove it:
// Check for and remove the BOM if present
bom := []byte{0xEF, 0xBB, 0xBF}
if bytes.HasPrefix(data, bom) {
data = data[len(bom):] // Strip BOM
}The crucial piece is here, once we have set up our data structures. We loop through the chapters and verses, building a payload of documents which we send to the BulkIndexer in the background.
for _, book := range booksData {
for chapterIndex, verses := range book.Chapters {
for verseIndex, verseText := range verses {
verseNum := verseIndex + 1 // Verse numbers typically start at 1
docID := fmt.Sprintf("%s-%d-%d", book.Abbrev, chapterIndex+1, verseNum)
doc := map[string]interface{}{
"abbrev": book.Abbrev,
"chapter": chapterIndex + 1,
"verse": verseNum,
"en": verseText,
}
data, err := json.Marshal(doc)
if err != nil {
log.Printf("Could not encode document %s: %s", docID, err)
continue
}
err = bulkIndexer.Add(
context.Background(),
esutil.BulkIndexerItem{
Action: "index",
DocumentID: docID,
Body: bytes.NewReader(data),
OnSuccess: func(ctx context.Context, item esutil.BulkIndexerItem, resp esutil.BulkIndexerResponseItem) {
// Handle success
},
OnFailure: func(ctx context.Context, item esutil.BulkIndexerItem, resp esutil.BulkIndexerResponseItem, err error) {
// Handle error
log.Printf("Failed to index document %s: %s", item.DocumentID, err)
},
},
)
if err != nil {
log.Fatalf("Error adding document to bulk indexer: %s", err)
}
}
}
}
if err := bulkIndexer.Close(context.Background()); err != nil {
log.Fatalf("Error closing bulk indexer: %s", err)
}Go is ideal for this as it has excellent parallel concurrency. We can use background workers.
To test it after changes:
go mod tidy
cd src/elasticbible/import
go run main.go -file="../resources/data/en_bbe.json" -host="https://localhost:9200" -username="elastic" -password="somepassword" -index="bible"To build the .exe when we're done:
cd src/elasticbible/import
go build -o ../../../bin/import.exe .And to run it:
cd bin/
./import.exe -file="../resources/data/en_bbe.json" -host="https://localhost:9200" -username="elastic" -password="somepassword" -index="bible"In 1-2 seconds, we have 31,000+ records in Elasticsearch which look like this in Elasticvue:
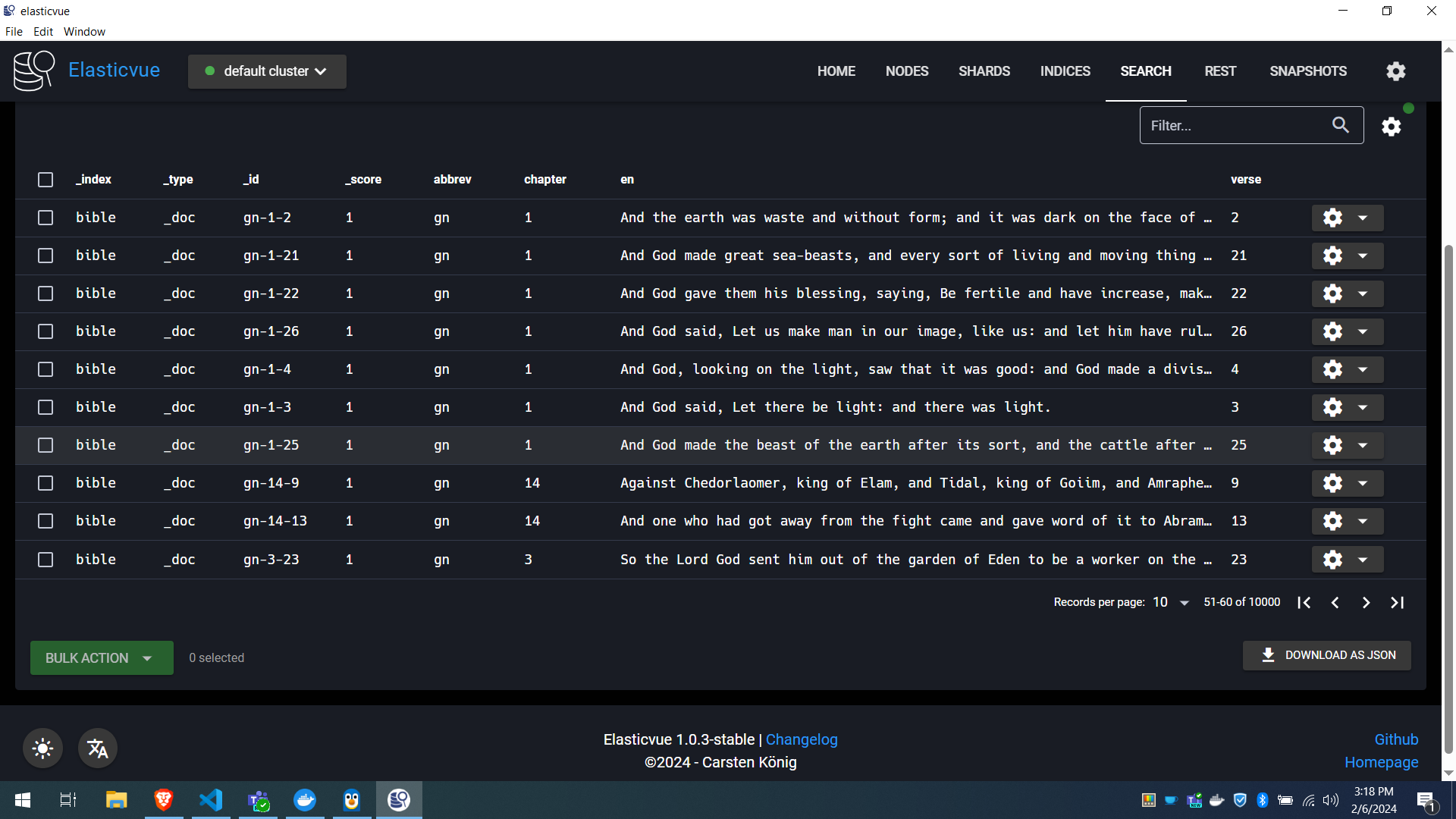
We can search directly in here to start off with.
A Client To Search The Data
Now, we can just search in Elasticvue, obviously. For example, inside the index, we can run a custom query. We start this way to ensure our search is working properly and producing the results we want, with the correct accuracy. Most of the problems can be fixed here.
We can search any of the language fields for the word "eagle":
{
"query": {
"bool": {
"should": [
{
"match": {
"en": {
"query": "eagle",
"fuzziness": "AUTO"
}
}
},
{
"match_phrase": {
"en": "eagle"
}
}
],
"minimum_should_match": 1
}
}
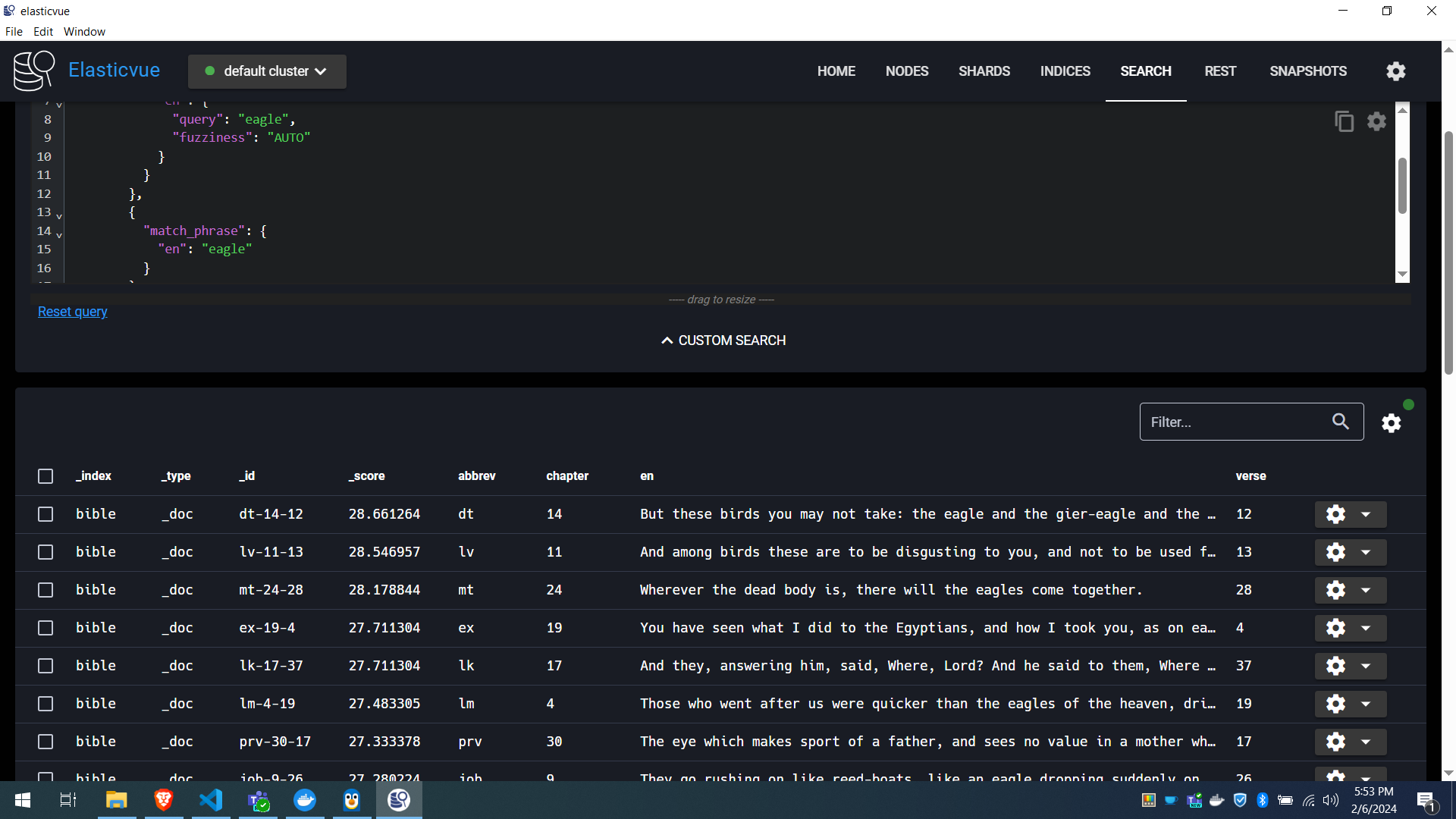
}We have 33 pages of results, showing 100 results per page. The top hit. with a score of 28.661264, is:
{
"abbrev": "dt",
"chapter": 14,
"en": "But these birds you may not take: the eagle and the gier-eagle and the ospray;",
"verse": 12
}
At this point, we can connect to Elasticsearch any way we like. But for the purposes of this demonstration, we will create a command-line program which lists results in the terminal; each on a new line.
Full code is here: https://github.com/devilslane-com/bible-golang-elasticsearch/blob/develop/src/elasticbible/search/main.go
We need to construct a JSON payload for the query for the Go client library to use, as above:
query := map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"should": []interface{}{
map[string]interface{}{
"match": map[string]interface{}{
"en": map[string]interface{}{
"query": searchText,
"fuzziness": "AUTO",
},
},
},
map[string]interface{}{
"match_phrase": map[string]interface{}{
"en": searchText,
},
},
},
"minimum_should_match": 1,
},
},
"highlight": map[string]interface{}{
"fields": map[string]interface{}{
"en": map[string]interface{}{},
},
},
"size": maxResults,
}
var buf strings.Builder
if err := json.NewEncoder(&buf).Encode(query); err != nil {
log.Fatalf("Error encoding query: %s", err)
}
res, err := es.Search(
es.Search.WithContext(context.Background()),
es.Search.WithIndex(esIndex),
es.Search.WithBody(strings.NewReader(buf.String())),
es.Search.WithPretty(),
)
if err != nil {
log.Fatalf("Error getting response: %s", err)
}
defer res.Body.Close()Once we have some results, we highlight the search term with a regular expression, and make it more readable with pretty colours:
searchTermRegex, err := regexp.Compile(`(?i)` + regexp.QuoteMeta(searchText))
if err != nil {
fmt.Printf("Error compiling regex: %v\n", err)
return
}
blue := color.New(color.FgBlue).SprintFunc()
magenta := color.New(color.FgMagenta).SprintFunc()
green := color.New(color.FgGreen).SprintFunc()
for _, hit := range r.Hits.Hits {
bookChapterVerse := blue(fmt.Sprintf("%s %d:%d", hit.Source.Book, hit.Source.Chapter, hit.Source.Verse))
score := magenta(fmt.Sprintf("[%.4f]", hit.Score))
// Highlight all instances of the search term within the verse text
verseTextHighlighted := searchTermRegex.ReplaceAllStringFunc(hit.Source.Text, func(match string) string {
return green(match) // Apply green color to each match
})
fmt.Printf("%s %s %s\n", bookChapterVerse, verseTextHighlighted, score)
}To test it after changes:
cd src/elasticbible/search
go run main.go -host="https://localhost:9200" -index="bible" -username="elastic" -password="somepassword"
-text="lion" -max=10This is annoying, so let's set some environmental vars we can also use with Docker.
export ES_HOST=https://localhost:9200
export ES_INDEX=bible
export ES_USERNAME=elastic
export ES_PASSWORD=somepassword
export MAX_RESULTS=20To build the .exe when we're done:
cd src/elasticbible/search
go build -o ../../../bin/search.exe .And to run it with args:
cd bin/
./search.exe -host="https://localhost:9200" -index="bible" -username="elastic" -password="somepassword"
-text="lion" -max=10Or without, simply:
cd bin/
./search.exe -text="lion"We get some simple, colourful results, which correspond to one Elasticsearch document per line, and their score.

na 2:11 Where is the lions hole, the place where the young lions got their food, where the lion and the she-lion were walking with their young, without cause for fear? [22.6668]
ez 19:2 What was your mother? Like a she-lion among lions, stretched out among the young lions she gave food to her little ones. [22.4338]
jr 51:38 They will be crying out together like lions, their voices will be like the voices of young lions. [22.2674]
job 4:10 Though the noise of the lion and the sounding of his voice, may be loud, the teeth of the young lions are broken. [21.9686]
gn 49:9 Judah is a young lion; like a lion full of meat you have become great, my son; now he takes his rest like a lion stretched out and like an old lion; by whom will his sleep be broken? [21.9568]
job 38:39 Do you go after food for the she-lion, or get meat so that the young lions may have enough, [21.8859]
1kgs 7:29 And on the square sides between the frames were lions, oxen, and winged ones; and the same on the frame; and over and under the lions and the oxen and the winged ones were steps. [21.8486]
prv 26:13 The hater of work says, There is a lion in the way; a lion is in the streets. [21.8388]
ez 19:6 And he went up and down among the lions and became a young lion, learning to go after beasts for his food; and he took men for his meat. [21.6412]
ps 17:12 Like a lion desiring its food, and like a young lion waiting in secret places. [21.5352]Eh, voila. You have a digital bible you can search. And plenty of time to spare.